1、问题与数据
某研究者已知受教育程度可以影响政治兴趣,即如果将受试者的受教育程度分为“School”、“College”和“University”3个等级(级别依次递增),他们对政治的兴趣随受教育程度的增加而增加。
该研究者拟进一步分析受试者这种受教育程度与政治兴趣的相关关系是否受性别影响。他计划招募60位受试者,包括30位男性和30位女性。每一个性别中,受试者的受教育程度均分为3类:“School”、“College”和“University”,每类10人。
该研究者采用问卷测量受试者的政治兴趣,受试者得分在0-100之间分布,分数越高,政治兴趣越强。
最终,收集受试者政治兴趣(political_interest)、性别(gender)和受教育程度(education_level)等变量信息,部分数据如下:
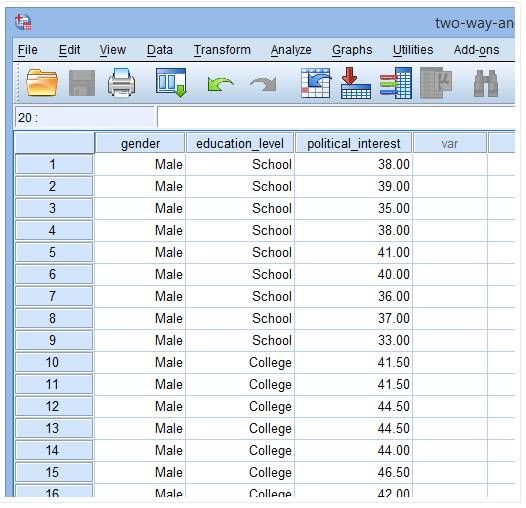
注释:在本研究中,“School”是指16岁之前接受的教育程度,“College”是指在16到18岁之间的教育程度,“University”是指18岁以上接受的教育程度。
2、对问题的分析
研究者已知一个自变量(受教育程度)对因变量(政治兴趣)的影响,想判断另一个自变量(性别)对这一相关关系是否存在作用。针对这种情况,我们可以使用双因素方差分析,但需要先满足6项假设:
假设1:因变量是连续变量
假设2:存在两个自变量,且都是分类变量
假设3:具有相互独立的观测值
假设4:任一分类中不存在显著异常值
假设5:任一分类中残差近似正态分布
假设6:任一分类都具有等方差性
那么,进行双因素方差分析时,如何考虑和处理这6项假设呢?
3、对假设的判断
3.1 假设1-3
因变量是连续变量;存在两个自变量,且都是分类变量。这两个假设与研究设计有关,需要根据实际情况判断。
至于假设3,我们之前的章节(如简单线性回归分析)中介绍过使用Durbin-Watson检验判断观测值是否相互独立的方法,这里不再赘述。同时,我们也认为观测值是否相互独立主要与研究设计有关,也需根据实际情况判断。
3.2 假设4-6
检验假设4-6需要用到残差,因此我们先运行双因素方差分析的SPSS操作,得到主要结果和相应残差变量后,再逐一进行对假设的检验。
3.2.1 主要SPSS操作
(1) 在主菜单点击Analyze→General Linear Model→Univariate
出现下图:
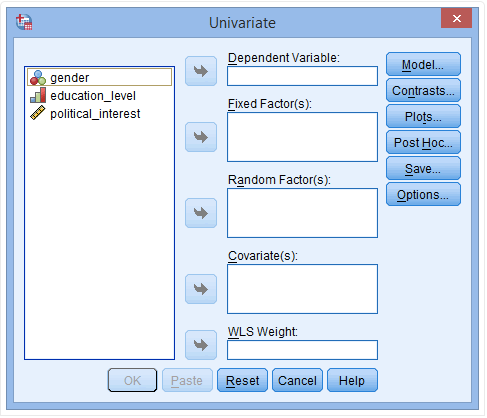
(2) 分别将political_interest放入Dependent Variable栏,性别(gender)和education_level放入Fixed Factor(s)栏
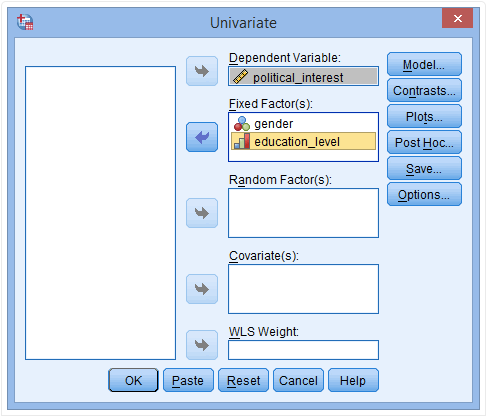
(3) 点击Plots,弹出下图
(4) 分别将gender和education_level放入Separate Lines和Horizontal Axis栏
(5) 点击Add,Plots栏内出现education_level*gender标识
(6) 分别将gender和education_level放入Horizontal Axis和Separate Lines栏
(7) 点击Add,Plots栏内出现gender *education_level标识
(8) 点击Continue→Options,弹出下图:
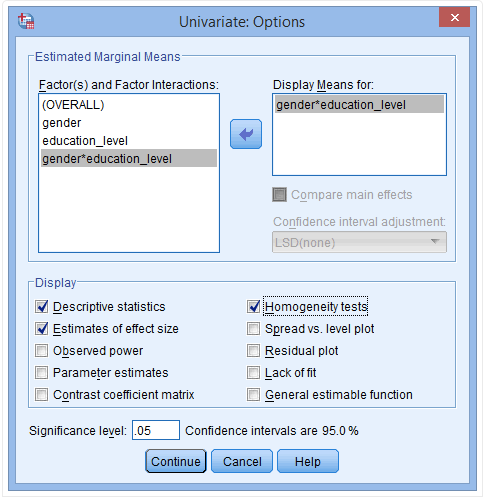
(9) 将gender *education_level放入Display Means for栏中,并在Display下点击Descriptive statistics、Estimates of effect size和Homogeneity tests
(10) 点击Continue→Save,弹出下图:
(11) 在Predicted Values中点击Unstandardized,并在Residuals中点击Unstandardized和Studentized
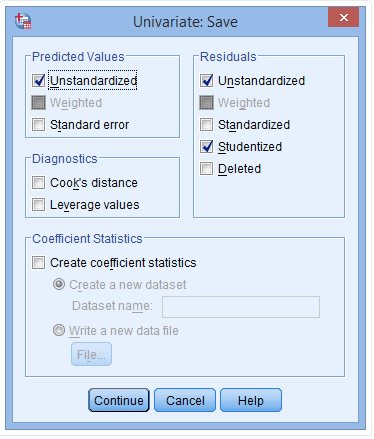
(12) 点击Continue→OK
上述操作将可以得到双因素方差分析的结果,并生成3个新变量:预测值(PRE_1),残差(RES_1)和学生化残差(SRE_1)。在对假设4-6的检验中,我们将用到这些新生变量。
但是,在检验假设4和假设5之前,我们还需要先拆分数据(即将数据根gender和education_level均分成6类),运行检验操作,再合并数据。
-
拆分数据
(1) 点击Data→Split File
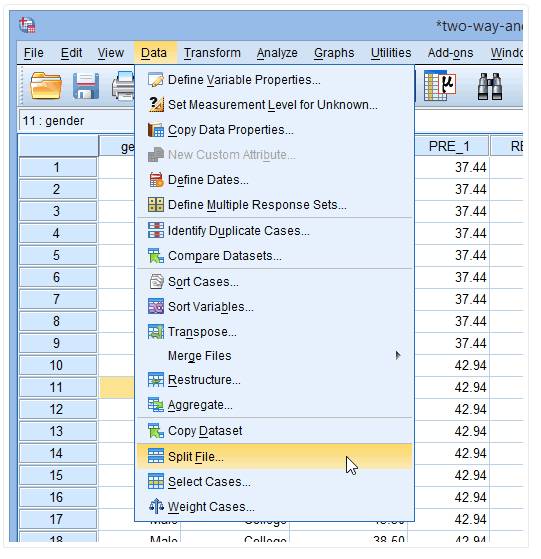
出现下图:
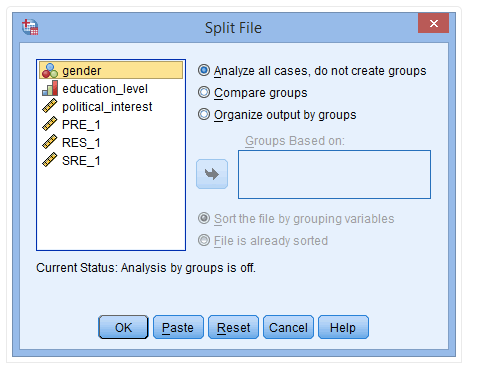
(2) 点击Compare groups
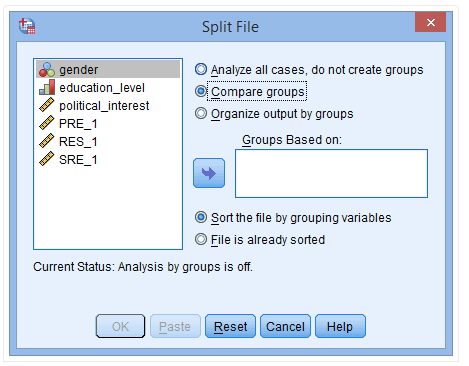
(3) 将gender和education_level放入Groups Basedon栏
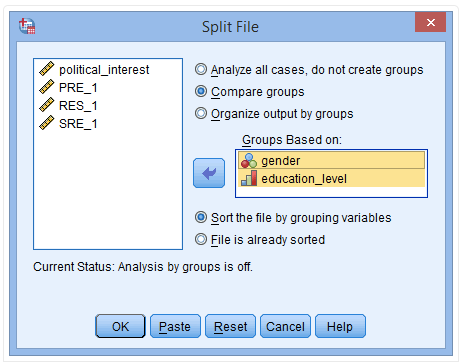
(4) 点击OK
-
针对每一分类,检验异常值(假设4)和残差正态性(假设5)
(1) 点击Analyze→Descriptive Statistics→Explore
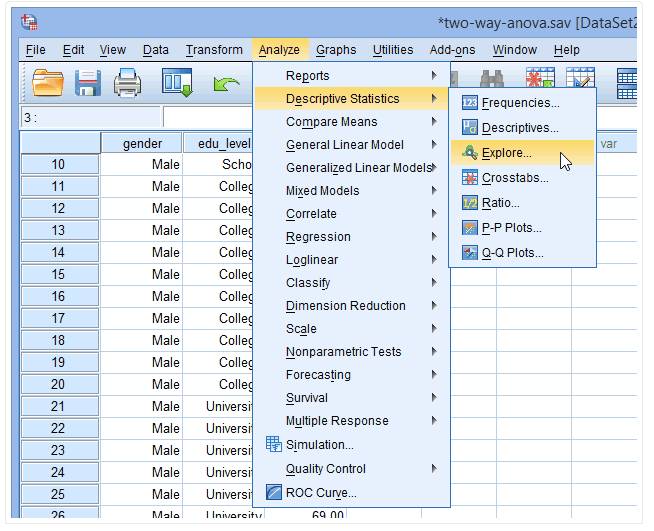
出现下图:
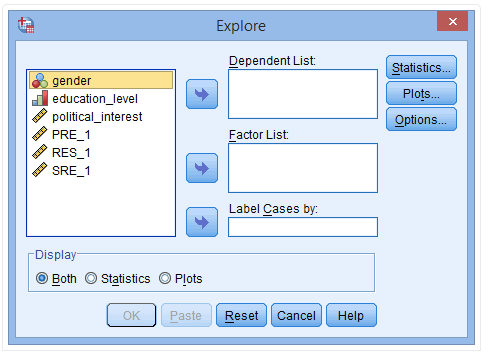
(2) 将RES_1放入Dependent List栏
(3) 点击Plots,弹出下图:

(4) 去掉点选Descriptive栏中的Stem-and-leaf,点选Normality plots with tests
(5) 点击Continue
(6) 在Display栏中点击Plots
(7) 点击OK
3.2.2 假设4:任一分类中不存在显著异常值
与其他方差分析一样,双因素方差分析对异常值非常敏感。这些数据不仅会扭曲各分类之间的差异,还会影响结果的外推性。因此,我们必须充分重视分析中的异常值。
经上述SPSS操作,软件会自动输出本研究中每一分类的箱式图,共6个。以下面两个举例:
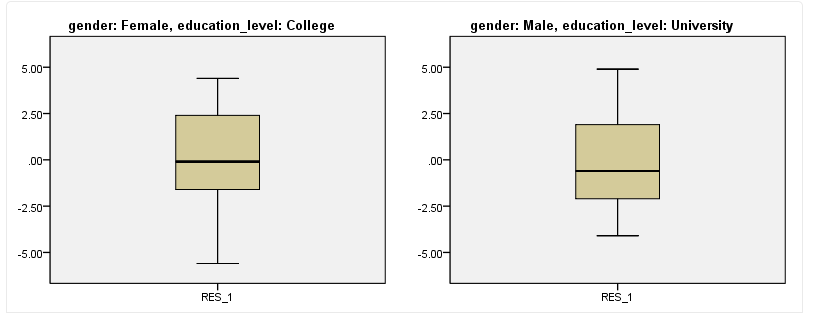
左侧是女性、受教育程度为“College”组的箱式图,未提示存在异常值。右侧是男性、受教育程度为“University”组的箱式图,也未提示异常值。本研究的其他4组的箱式图也是同样的情况,证明该研究数据满足假设4。
为了让大家更清楚地解释使用箱式图判断异常值的方法,我们以一个存在异常值的箱式图举例如下:
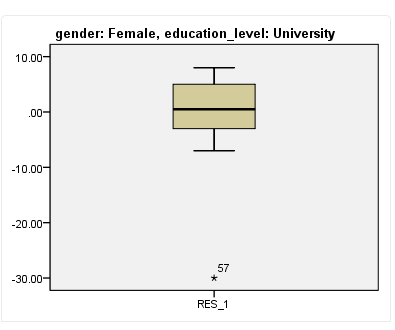
该图提示,在女性、学历程度为“University”组存在异常值,第57位(row number)受试者的政治兴趣非常低,应考虑进行异常值调整或剔除。
如果存在异常值,我们应该如何做呢?
如果不希望或者不能剔除异常值,我们可以将其保留。可以采取以下4种办法:
(1) 选择更稳健的双因素方差模型;
(2) 调整异常值,如用第二大极值取代异常值;
(3) 对自变量进行数据转换;
(4) 确认异常值存在不会影响结果,如分别运行纳入和不纳入异常值的模型,若结果没有差异,可以保留异常值。
当然,我们也可以直接剔除异常值,但这往往是我们迫不得已的做法。因为我们进行数据分析是为了根据样本结果推论总体,但直接剔除异常值就相当于不再考虑这部分人的信息,忽略了他们在总体人群中的作用。
如果一定要剔除异常值,我们就应该在报告中描述被剔除者的信息(数据以及对研究结果的影响)。这样读者就可以清楚地了解到我们剔除异常值的原因以及这些异常值可能存在的影响,消除大家对研究结果的质疑。
3.2.3 假设5:任一分类中残差近似正态分布
本研究采用Shapiro-Wilk检验数据正态性。看过其他章节(如多重线性回归)后,大家应该知道检验数据正态性的方法有很多种。本研究采用Shapiro-Wilk检验的原因在于每一组中的样本量较小,而Shapiro-Wilk检验主要适用于这种小样本的正态性检验(样本量<50)。
SPSS输出Shapiro-Wilk检验结果如下:
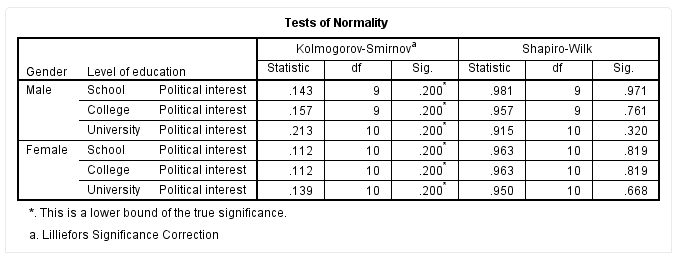
一般来说,如果Shapiro-Wilk检验的P值小于0.05,我们就认为数据不符合正态分布。从上表可知,本研究中每一个分组的P值都大于0.05,即任一分类中残差近似正态分布,满足假设5。
如果残差不接近正态分布,我们应该如何做呢?
我们可以采取以下4种办法:
(1) 转换数据;
(2) 因为方差分析对假设5并不是非常敏感,即使残差不接近正态分布,我们也可以尝试采用双因素方差模型;
(3) 检验模型结果。因为没有可以替代双因素方差分析的非参数检验方法,我们只能对比数据转换前后的模型,判断直接采用双因素方差分析是否合理;
(4) 选择更稳健的双因素方差模型。
3.2.4 假设6:任一分类都具有等方差性
任一分类都具有等方差性是双因素方差分析的基本假设,可以通过Levene方差齐性检验完成。
通过3.2.1的操作,SPSS输出结果如下:

一般来说,如果Levene方差齐性检验的P值大于0.05,我们就认为数据符合等方差性。从上表可知,本研究中Levene方差齐性检验的P值为0.061,大于0.05,即任一分类都具有等方差性,满足假设6。
如果方差不齐,我们应该如何做呢?
我们可以采取以下4种办法:
(1) 转换数据;
(2) 如果各组样本量一致、符合正态性并且方差最大组与最小组的比值小于3,那么我们认为即使方差不齐,也可以尝试采用双因素方差模型;
(3) 选择更稳健的模型,如一般线性模型;
(4) 采用加权最小二乘法回归方程。
3.2.5 合并数据
在解释结果之前,我们先来把数据合并,具体操作如下:
(1) 点击Data→Split File
出现下图:
(2) 点击Analyze all cases, do not create groups
(3) 点击OK
4、结果解释
在解释双因素方差分析的结果前,我们需要先进行以下分类,再根据分类,采用不同的解释方法:
(1) 如果自变量之间不存在交互作用,进行主效应分析;
(2) 如果自变量之间存在交互作用,进行简单主效应和交互作用对照分析。
4.1 结果判断
4.1.1 判断是否存在交互作用
采用双因素方差分析的一个出发点就是判断自变量之间是否存在交互作用,如本研究中的gender和education_level变量。在进行统计检验之前,我们可以通过简图了解自变量的交互情况,如下示例:
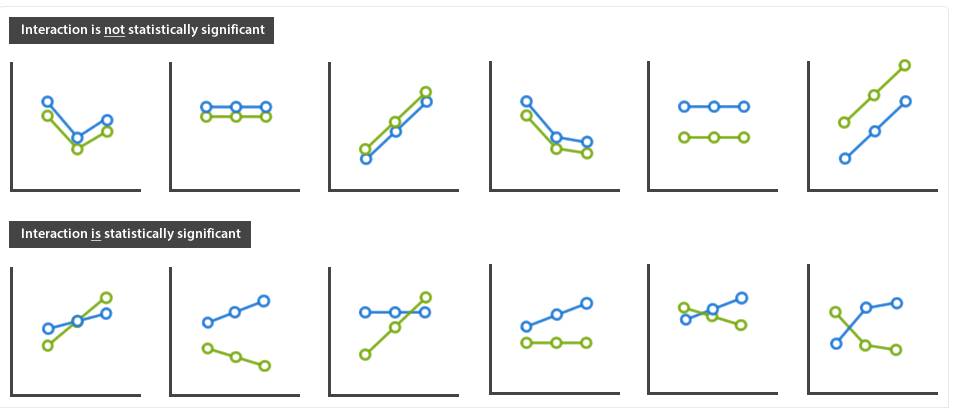
一般来说,如果两条线平行或即使延长X轴也不会相交,我们就可以初步判断自变量之间不存在交互作用。但如果两条相交或延长X轴后可能相交,我们就认为自变量之间可能存在交互作用。
本研究中,SPSS输出结果如下:
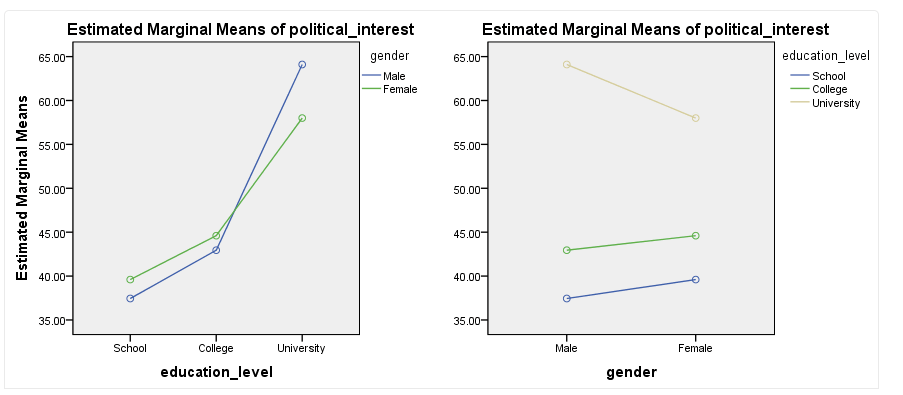
这两张图都提示,本研究中受教育程度与性别可能在对政治兴趣的影响上存在交互作用。左上图更为直观,我们就以左上图为例进行介绍。
具体来说,男性和女性的政治兴趣都随着受教育程度的增加而增加,尤其是当受教育程度达到“University”水平时,增加幅度更加明显。但是,男性和女性的增加趋势有所不同。
男性的受教育程度在“School”和“College”时政治兴趣比女性低;但当男性的受教育程度达到“University”时,其政治兴趣就比女性高了。可见,在提高受教育程度增加政治兴趣的过程中,男性比女性获益更大。
尽管上图可以提供自变量之间交互作用的直观结果,但是我们并不能确定这些样本结果是否可以代表总体,即图形结果是否会受到抽样误差的影响。因此,我们仍需要依据统计检验进行判断。SPSS输出检验结果如下:
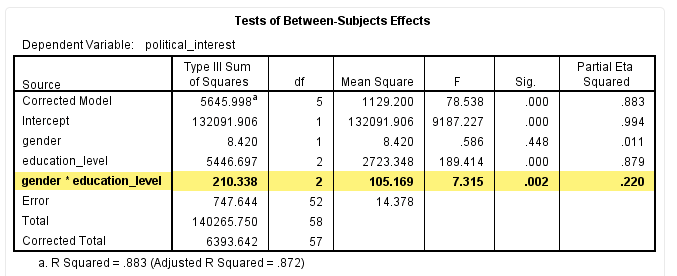
该表中各指标的含义如下:

结果显示,本研究中交互项具有统计学意义,F(2,52)=7.315,P = 0.002,偏η2=0.220,提示性别和受教育程度在对政治兴趣的影响上存在交互作用。如果P > 0.05,则说明交互项没有统计学意义,两个自变量之间不存在交互作用。
4.1.2 当存在交互作用时
如果自变量之间存在交互作用,我们就需要分别考虑自变量的简单主效应。但在这之前,我们需要区分同序交互(ordinal interactions)和异序交互(disordinal interactions)。
其中,同序交互是指交互作用没有重叠或交叉,异序交互是指交互作用存在重叠或交叉,如下示例:
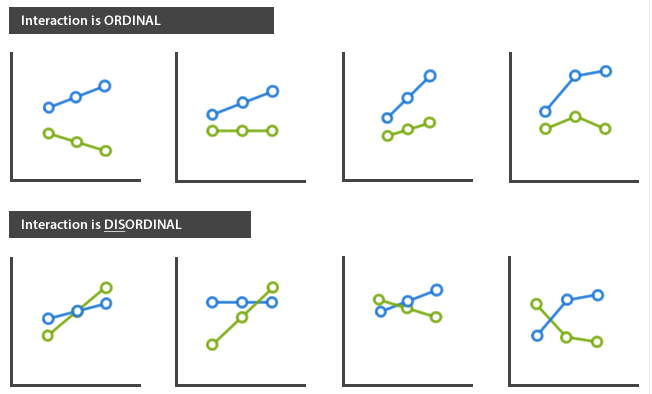
本研究中,性别和受教育程度存在异序交互作用。我们将在后文中详细介绍。
4.1.3 当不存在交互作用时
如果不存在交互作用,不同自变量的简单主效应是一致的,我们可以直接讨论主效应结果。也有研究者存在质疑,既然交互项没有统计学意义,是否还需要在模型中保留交互项?考虑到研究样本推论总体的可信性,我们仍建议在双因素方差模型中保留交互项,供大家参考。
4.2 简单主效应
4.2.1 简单主效应的SPSS操作
(1) 点击Analyze→General Linear Model→Univariate
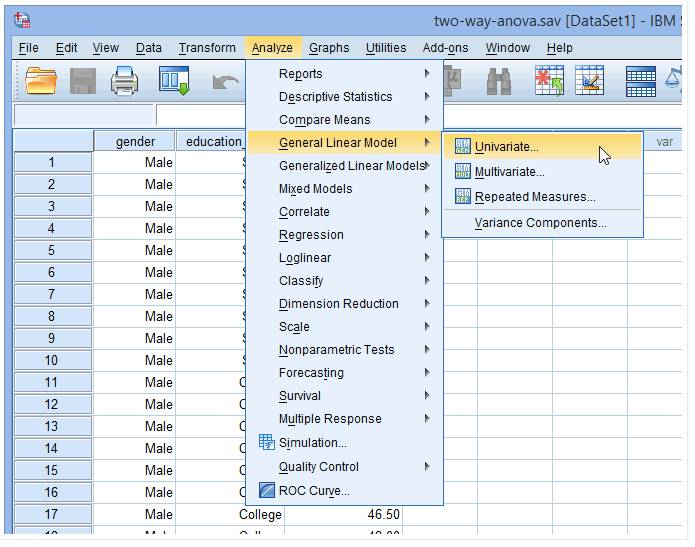
出现下图:
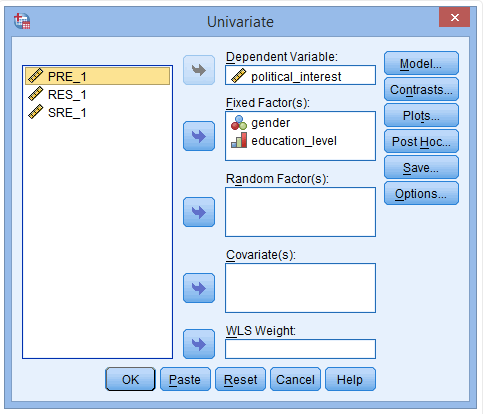
(2) 点击Save,弹出下图:
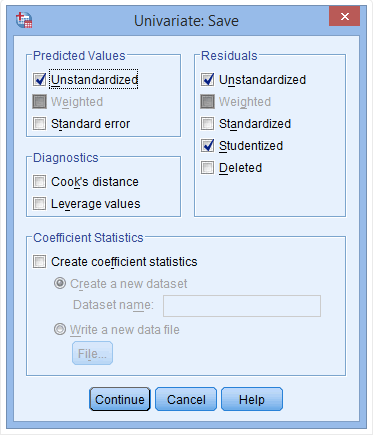
(3) 去掉在Predicted Values中Unstandardized的点选,并去掉在Residuals中Unstandardized和Studentized的点选
(4) 点击Continue→Paste,弹出IBM SPSS Statistics Syntax Editor界面
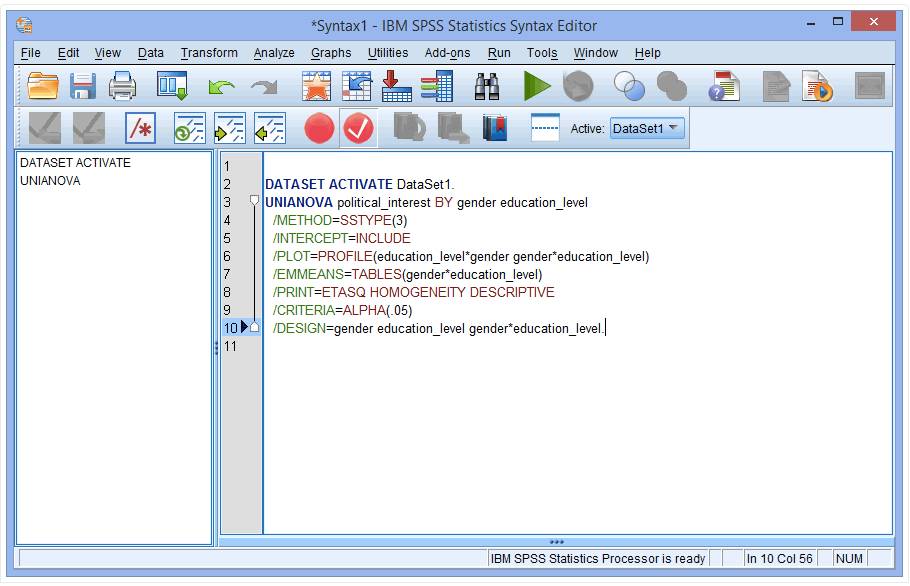
(5) 在/EMMEANS=TABLES(gender*education_level)后输入COMPARE(gender)ADJ(BONFERRONI),如下:
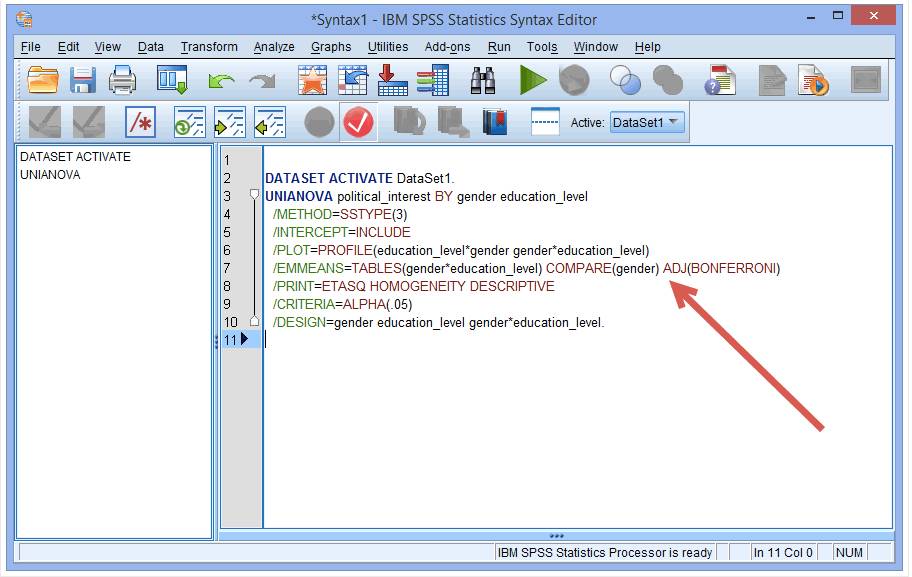
解释:COMPARE(gender)是指根据gender变量提供简单主效应结果;ADJ(BONFERRONI)是指对各组进行多重比较,并对结果进行Bonferroni调整。如果不需要多重比较,也可以去掉这句语法。
(6) 复制该语句,并将COMPARE(gender)改为COMPARE(education_level)
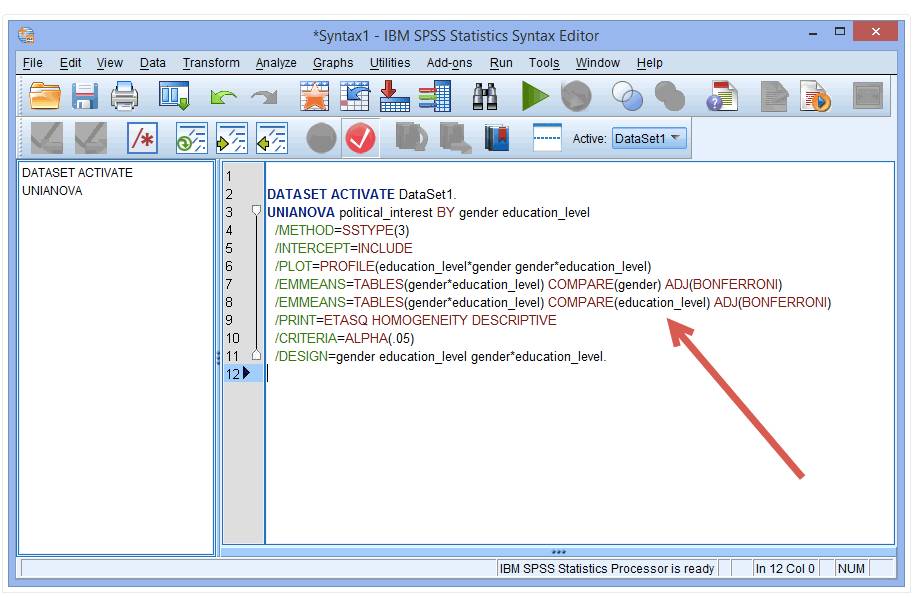
解释:COMPARE(education_level)是指根据education_level变量提供简单主效应结果。
(7) 点击Run→ALL
4.2.2 简单主效应的解释
对二分类变量简单主效应的解释比多分类变量容易,所以我们从性别变量的简单主效应开始:
-
性别的简单主效应
性别的简单主效应就是在不同的受教育程度中分析性别的作用。我们先从下图中得到一些直观的认识:
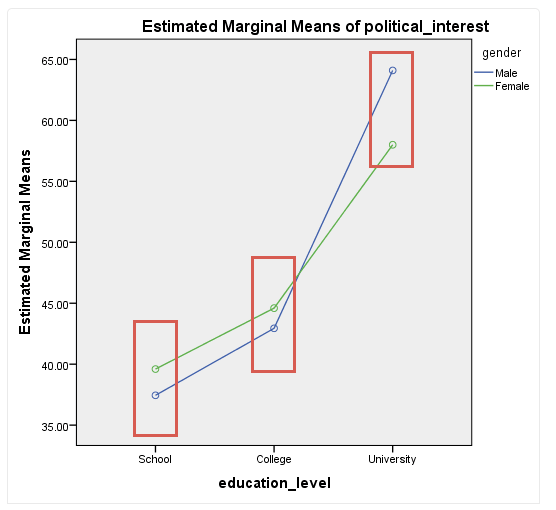
从图中可以看出,在不同的受教育程度下,不同性别对政治兴趣的影响不同,统计结果如下:
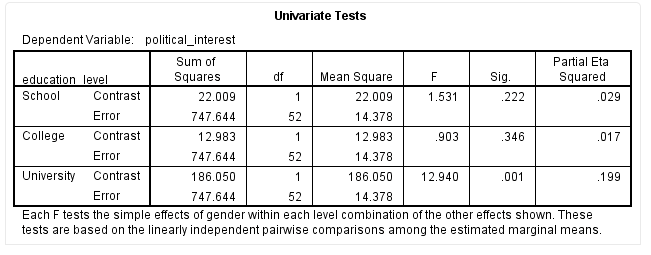
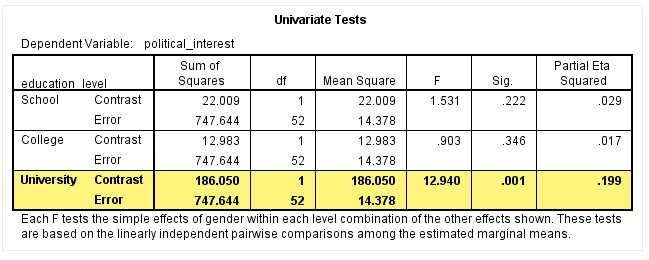
以“University”学历中不同性别对政治兴趣的简单主效应为例,如下标黄部分:
该表中各指标的含义如下:

结果显示,F(2,52)=12.94,P = 0.001,偏η2=0.199,提示“University”学历中不同性别对政治兴趣的简单主效应不同,差异具有统计学意义。
Pairwise Comparisons表格提示该组数据的均值比较结果,如下:
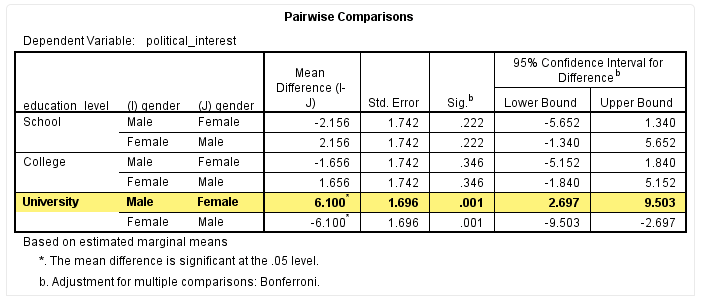
从该表可以看出,“University”学历中不同性别的政治兴趣不同,差异具有统计学意义(P=0.001),与Univariate Tests结果一致。若想要了解“University”学历中不同性别具体的政治兴趣评分,需要绘制统计描述表格,如下:
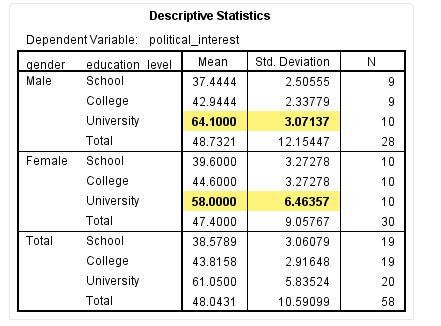
该表提示,“University”学历中男性的政治兴趣为64.1±3.07,女性的政治兴趣为58.0±6.46。整合以上Univariate Tests、Pairwise Compairsons和Descriptive Statistics三个表格的结果,我们就可以得到关于“University”学历中不同性别对政治兴趣简单主效应的全面分析,其他学历下性别的简单主效应结果的分析方法与此类似,我们就不再赘述。
-
受教育程度的简单主效应
受教育程度的简单主效应就是在不同性别下分析不同受教育程度的作用。我们先从下图中得到一些直观的认识:
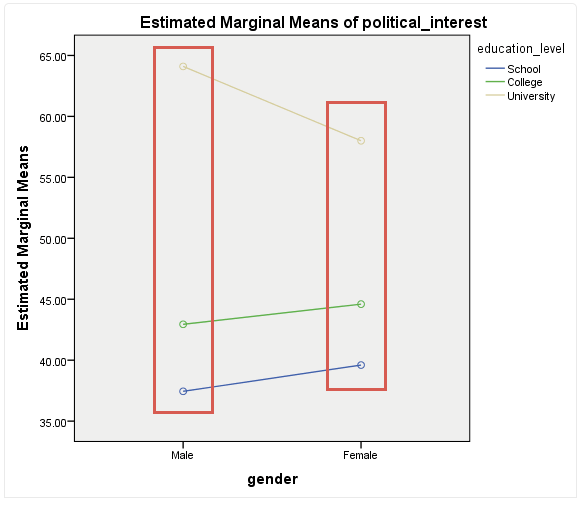
从图中可以看出,在不同性别下,不同受教育程度对政治兴趣的影响不同,统计结果如下:
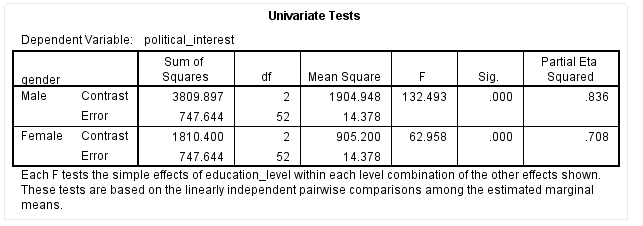
以女性不同受教育程度对政治兴趣的简单主效应为例,如下标黄部分:
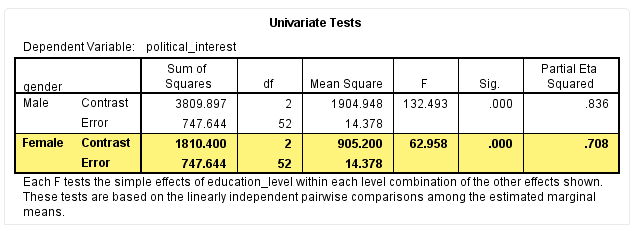
该表中各指标的含义如下:

结果显示,F(2,52)=62.96,P < 0.001,偏η2=0.708,提示不同受教育程度女性对政治兴趣的简单主效应不同,差异具有统计学意义。
Pairwise Comparisons表格提示该组数据的均值比较结果,如下:
受教育程度是三分类变量,多重比较时需要对不同受教育程度进行两两比较,分为以下三种情况:
(1) “School”vs “College”
(2) “School”vs “University”
(3) “College”vs “University”
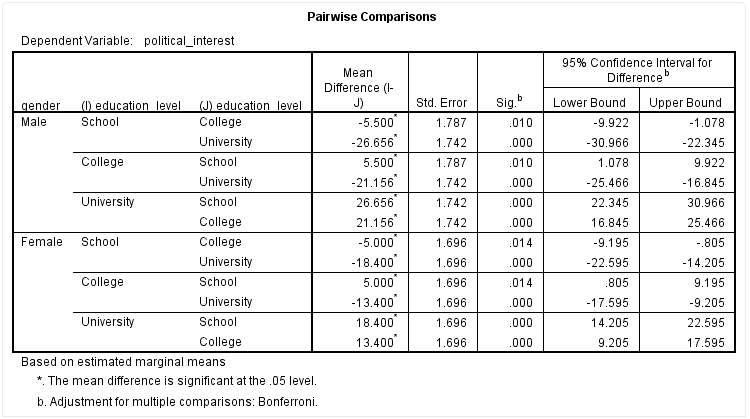
我们以女性中“College”与“School”的均值比较为例,如下标黄部分:
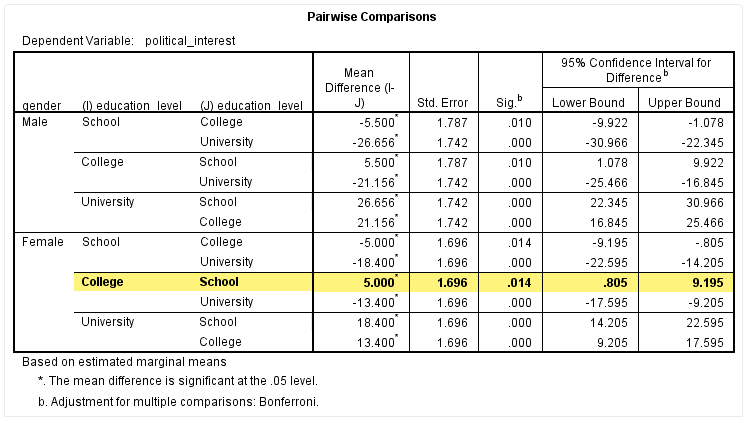
从该表可以看出,女性中“School”与“College”的政治兴趣不同,差异具有统计学意义(P=0.014),与Univariate Tests结果一致。
若想要了解女性“School”与“College”的具体政治兴趣评分,需要绘制统计描述表格,如下:
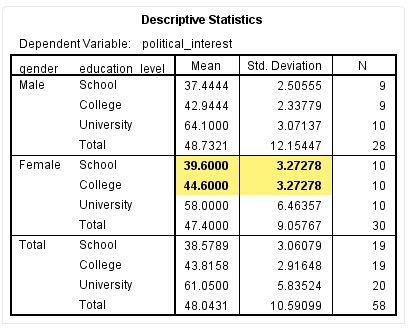
该表提示,女性“School”学历的政治兴趣为39.6±3.27,“College”学历的政治兴趣为44.6±3.27。整合以上Univariate Tests、Pairwise Compairsons和Descriptive Statistics三个表格的结果,我们就可以得到关于女性不同受教育程度对政治兴趣简单主效应的全面分析,男性不同受教育程度简单主效应结果的分析方法与此类似,我们就不再赘述。
4.3 主效应
4.3.1 主效应的SPSS操作
(1) 在主界面点击Analyze→General Linear Model→Univariate
出现下图:

(2) 点击Options
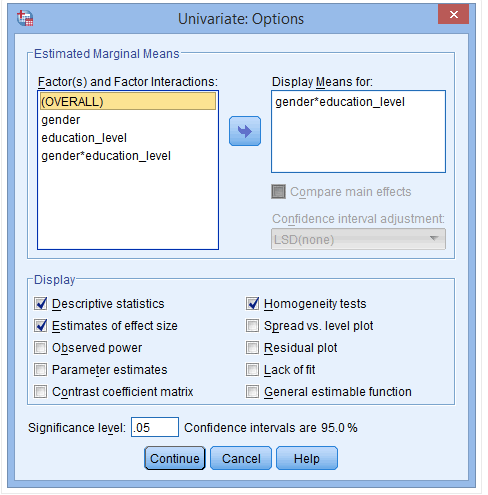
(3) 将gender和education_level放入Display Means for栏,激活Compare main effects,选择Confidence interval adjustment中的Bonferroni选项
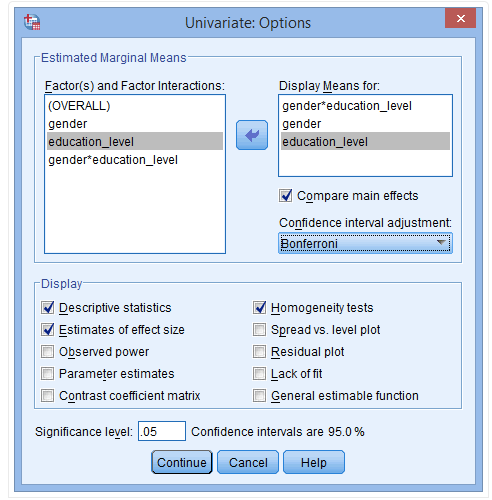
(4) 点击Continue→Post hoc,弹出下图:
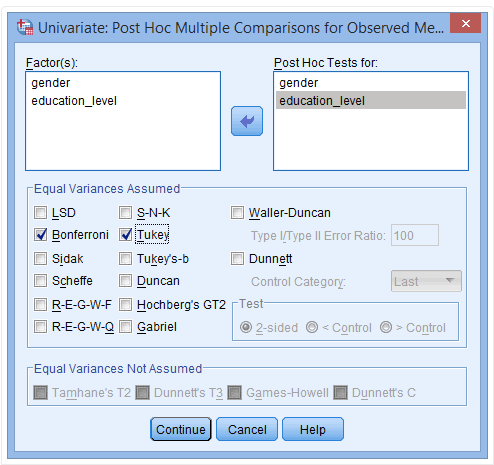
(5) 将gender和education_level放入Post Hoc Tests for栏,激活Equal Variances Assumed,点选Bonferroni和Tukey
(6) 点击Continue→OK
4.3.2 主效应的结果解释
在解释主效应之前,我们需要先区分研究为平衡设计(balanced design)还是非平衡设计(unbalanced design)。如果双因素方差分析中每组的样本量不同,那么该研究就是非平衡设计;如果每组的样本量相同,那就是平衡设计。
在实际工作中,即使在研究设计时是平衡设计,在研究结束时也可能成为非平衡设计。往往由于受试者的失访或拒访导致最终每组样本量的不同。例如,本研究在研究设计时拟每类招募10位受试者,共招募60位。但最终有的组收集了10例数据,有的组仅收集了9例,成为非平衡设计。
其实,平衡设计和非平衡设计的区别在于,非平衡设计中自变量对因变量变异的解释可能存在“重叠”,导致对因变量变异的过度解释。
在非平衡设计中,我们还需要选择计算加权边际均值(weighted marginal means)还是非加权边际均值(unweighted marginal means)。二者的区别在于加权边际均值考虑了每组样本量的不同,但是既往研究普遍推荐使用非加权边际均值,本研究亦是如此。
那么针对不同的双因素方差模型,我们应该如何解释主效应结果呢?
(1) 如果是平衡设计,我们采用SPSS输出Univariate: Post Hoc Multiple Comparisons for Observed Means分析结果;
(2) 如果是非平衡设计,且拟计算加权边际均值,我们读取Descriptive Statistics和Multiple Comparisons结果;
(3) 如果是非平衡设计,且拟计算非加权边际均值,我们读取Estimates和Pairwise Comparisons结果,如下:

在本研究中,我们采用的是非平衡设计,拟计算非加权边际均值,所以通过SPSS输出的Estimates表得到非加权均值,并通过Pairwise Comparisons表得到多重比较结果。其中,Estimates表结果如下:
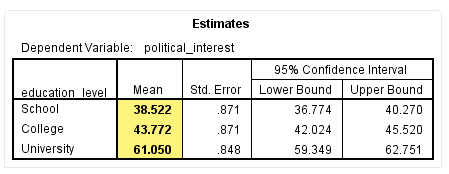
从该表的Mean栏,可以得到非加权边际均值,即本研究“School”“College”和“University”的非加权边际均值分别为38.52、43.77和61.05。
同时,我们也可以跟Descriptive Statistics表中加权边际均值进行比较,如下:
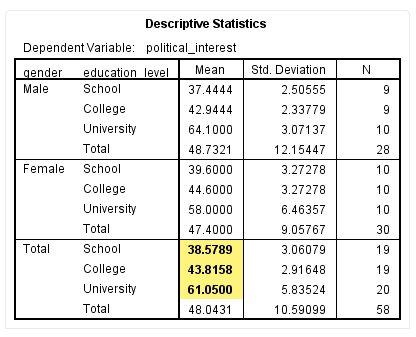
Descriptive Statistics表提示,本研究“School”“College”和“University”的加权边际均值分别为38.57、43.81和61.05。可见,加权边际均值和非加权边际均值并不完全相同。实际上,只有在平衡设计中,加权边际均值和非加权边际均值才会完全相等。其他情况下,这两个指标都是不同的。
-
性别的主效应结果
性别的主效应是指性别对政治兴趣的作用,而忽视不同受教育程度的影响。性别主效应非加权边际均值的计算方法如下:
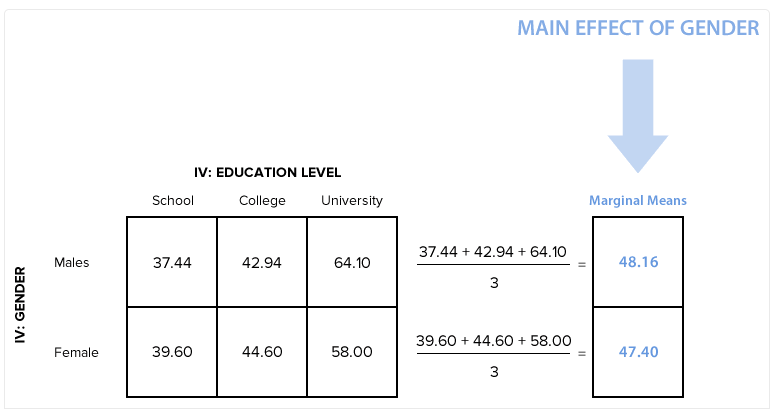
由图可知,在忽略了受教育程度的情况下,男性的边际均值为48.16,女性的边际均值为47.40。可推测,男性的政治兴趣比女性强。但我们还需要经过统计检验,如下:
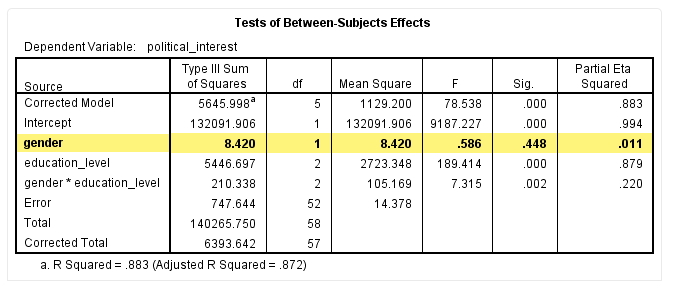
统计检验结果提示,P=0.448,大于0.05,即不同性别的主效应差异没有统计学意义。针对主效应差异不显著的情况,我们不用进一步讨论post hoc分析结果。
-
受教育程度的主效应结果
受教育程度的主效应是指受教育程度对政治兴趣的作用,而忽视不同性别的影响。与性别一样地,受教育程度主效应非加权边际均值的计算方法如下:
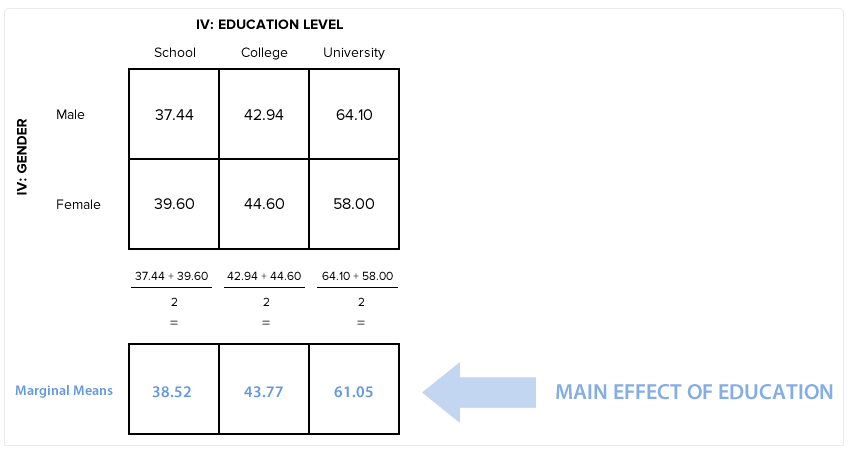
由图可知,在忽略了性别的情况下,“School”学历的边际均值为38.52,“College”学历的边际均值为43.77,“University”学历的边际均值为61.05。SPSS输出的Estimates表也提示该结果,与手算结果一致,如下:
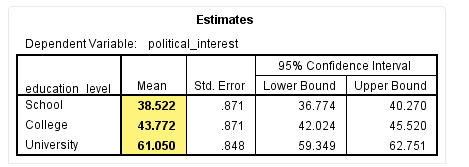
根据这一结果我们可推测,受教育程度越高,政治兴趣越强。但这一推测需要经过统计检验,如下:
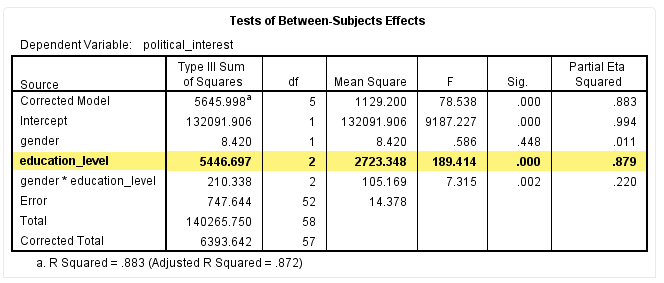
统计检验结果提示,P<0.001,即不同受教育程度的主效应差异有统计学意义。针对这种情况,我们还需要进一步分析Pairwise Comparisons表的结果,得到不同受教育程度下受试者的政治兴趣得分均值。
受教育程度是三分类变量,多重比较时需要对不同受教育程度进行两两比较,分为以下三种情况:
(1) “School”vs “College”
(2) “School”vs “University”
(3) “College”vs “University”
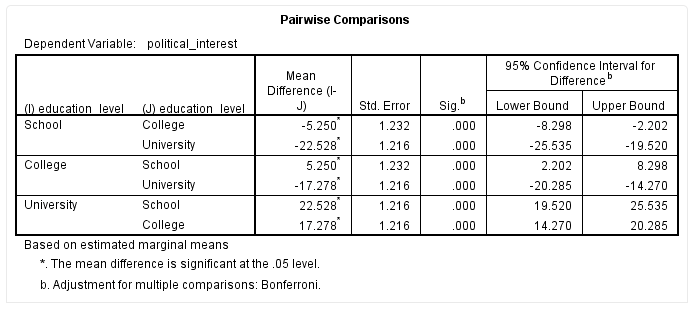
我们以“College”与“School”的边际均值比较为例,如下标黄部分:
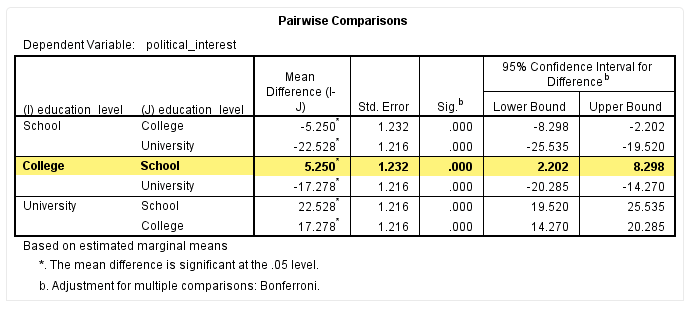
从该表可以看出,受教育程度为“School”与“College”的受试者政治兴趣不同,即“College”学历的政治兴趣评分比“School”学历的高5.25(95%CI为2.20-8.30),差异具有统计学意义(P<0.001)。其他分类分析方法类似,不再赘述。
整合以上Tests of Between-Subjects Effects、Pairwise Comparisons和Estimates三个表格的结果,就可以得到关于不同受教育程度对政治兴趣主效应的全面分析。
4.4 交互作用对照(interaction contrast)
4.4.1 交互作用对照的SPSS操作
(1) 在主菜单点击Analyze→General Linear Model→Univariate
出现下图:
(2) 点击Paste,弹出下图
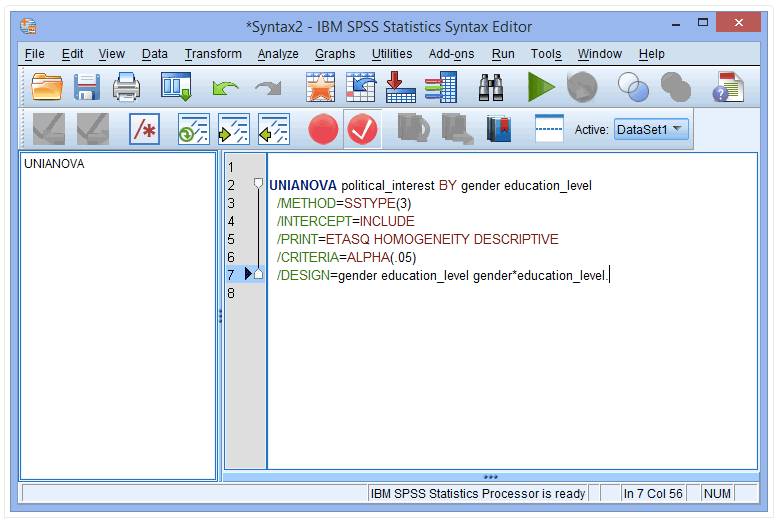
(3) 在/PRINT=ETASQ HOMOGENEITY DESCRIPTIVE输入
/LMATRIX=gender*education_level 0 1 -1 0 -1 1
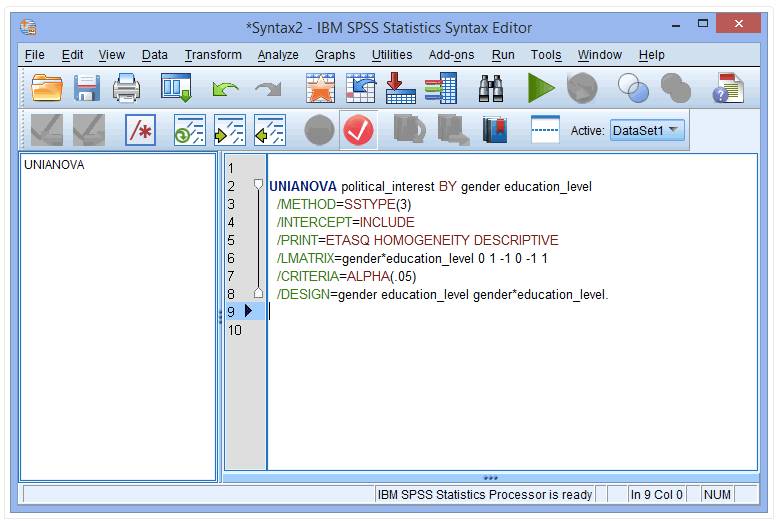
解释:/LMATRIX=gender*education_level 0 1 -1 0 -1 1中“0 1 -1 0 -1 1”分别对应的是School男性、College男性、University男性、School女性、College女性和University女性政治兴趣指标中用以计算差分的比较组。
其中,“0”的组别不参与比较,“-1”的组别作为参照组,本例中即为“College男性”和“University女性”两组的组合与“University男性”和“College女性”两组的组合之间的比较。大家也可以根据实际情况,调整比较组,只要相加得0即可。
(4) 点击Run→ALL
4.4.2 交互作用对照的结果解释
SPSS输出本研究交互作用对照分析的结果如下:
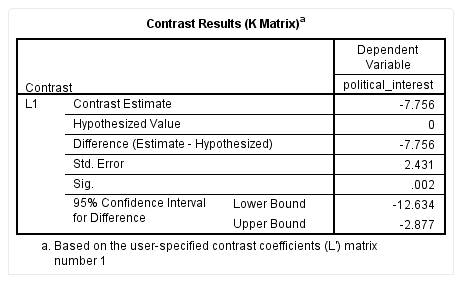
上表中“L1”是指针对第一组交互作用的对照分析。一般来说,当研究中只有一个交互项时,这个指标可以忽略不计(如本研究)。当研究中存在超过一个交互项时,该指标可以提醒研究者每组结果对应的变量。
在“Contrast Estimate”栏可以看待交互作用对照的实际值,即差分值(the value of the difference of the difference):
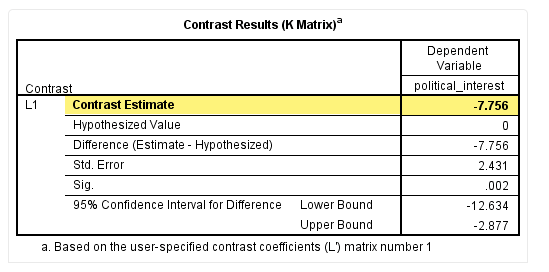
本研究中交互作用对照的实际值为-7.756。这个数值是怎么计算出来的呢?
在受教育程度为“College”的情况下,男性和女性政治兴趣评分的差值为44.60 – 42.94 = -1.66;在受教育程度为“University”的情况下,男性和女性政治兴趣评分的差值为64.10 – 58.00 = 6.10。
本研究交互作用对照的实际值就是这几项的差分,即-1.66 – 6.10 = -7.756,代表“College”学历男、女性政治兴趣评分的差值与“University”学历男、女性政治兴趣评分的差值的差。
“Sig”栏提示该指标的统计学检验结果,如下:
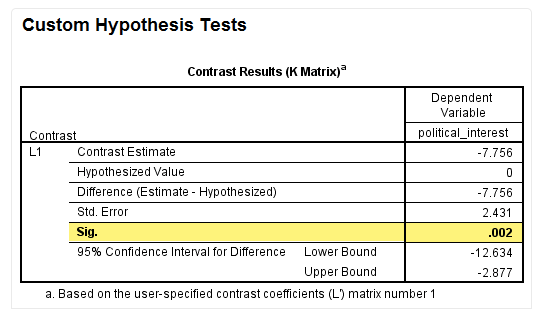
P=0.002,提示该差分值与0的差异存在统计学意义。95%CI值如下:
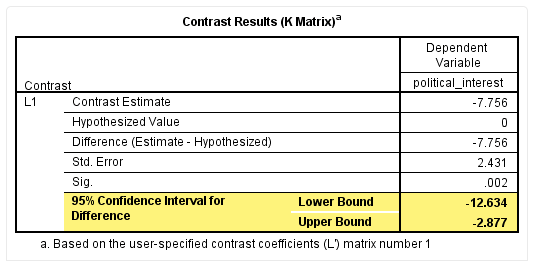
从“95% Confidence Interval for Difference”栏可以看出,该差分值的95%CI为-2.877到-12.634。综上,我们认为本研究的差分值为-7.756(95%CI为-2.877到-12.634),P=0.002。
5、撰写结论
5.1 自变量之间存在交互作用时,采用简单主效应和成对比较分析
采用双因素方差分析性别和受教育程度对政治兴趣的影响。除非特殊说明,本研究均使用均数±标准差反映数据情况,用箱式图检验异常值,用Shapiro-Wilk检验数据正态性,用Levene方差齐性检验判断等方差性。
结果显示,本研究数据没有异常值,残差接近正态分布(P>0.05),并且具有等方差性(P=0.061)。
在本研究中,性别和受教育程度在对政治兴趣的影响上存在交互作用,F(2,52)=7.315,P=0.002,偏η2=0.220。简单主效应分析提示,在不同的受教育程度下,不同性别受试者的政治兴趣不同:男性F(2,52)=62.96,P<0.001,偏η2=0.708;女性F(2,52)=132.493,P<0.001,偏η2=0.836。
采用成对比较分析每一类别的简单主效应结果。受教育程度为“School”、“College”和“University”女性的平均政治兴趣评分分别为39.60 ± 3.27、44.60 ± 3.27和58.00 ± 6.46。
其中,“School”学历女性的政治兴趣评分比“College”学历的低5.00(95%CI为0.81-9.20),P=0.014;比“University”学历的低18.40(95%CI为14.21-22.60),P<0.001。“College”学历女性的政治兴趣评分也比“University”学历的低13.40(95%CI为9.21-17.60),P<0.001。
受教育程度为“School”、“College”和“University”男性的平均政治兴趣评分分别为37.44 ± 2.51、42.94 ± 2.34和64.10 ± 3.07。
其中,“School”学历男性的政治兴趣评分比“College”学历的低5.50(95%CI为1.08-9.92),P=0.010;比“University”学历的低26.66(95%CI为22.35-30.97),P<0.001。“College”学历男性的政治兴趣评分也比“University”学历的低21.16(95%CI为16.85-25.47),P<0.001。
5.2 自变量之间存在交互作用时,采用交互作用对照分析
采用双因素方差分析性别和受教育程度对政治兴趣的影响。除非特殊说明,本研究均使用均数±标准差反映数据情况,用箱式图检验异常值,用Shapiro-Wilk检验数据正态性,用Levene方差齐性检验判断等方差性。结果显示,本研究数据没有异常值,残差接近正态分布(P>0.05),并且具有等方差性(P=0.061)。
在本研究中,性别和受教育程度在对政治兴趣的影响上存在交互作用,F(2,52)=7.315,P=0.002,偏η2=0.220。交互作用对照分析提示,“College”学历男性的政治兴趣评分比“College”学历女性低1.66;而“University”学历男性的政治兴趣评分比“University”学历女性高6.10。差分为-7.756(95%CI为-2.877到-12.634),P=0.002。
5.3 自变量之间不存在交互作用时,采用主效应和成对比较分析
采用双因素方差分析性别和受教育程度对政治兴趣的影响。除非特殊说明,本研究均使用均数±标准差反映数据情况,用箱式图检验异常值,用Shapiro-Wilk检验数据正态性,用Levene方差齐性检验判断等方差性。结果显示,本研究数据没有异常值,残差接近正态分布(P>0.05),并且具有等方差性(P=0.061)。
在本研究中,性别和受教育程度在对政治兴趣的影响上不存在交互作用,F(2,52)=1.108,P=0.092,偏η2=0.020。主效应分析提示,受教育程度对政治兴趣的影响具有统计学意义,F(2,52)=189.414,P<0.001,偏η2=0.879。
采用成对比较分析受教育程度的主效应结果。受教育程度为“School”、“College”和“University”受试者的政治兴趣评分的非加权边际均值分别为38.52 ± 0.871、43.77 ± 0.871和61.05 ± 0.848。
其中,“College”学历的政治兴趣评分比“School”学历的高5.25(95%CI为2.20-8.30),P<0.001;“University”学历的政治兴趣评分比“College”学历的高17.28(95%CI为14.27-20.29),P<0.001;“University”学历的政治兴趣评分比“School”学历的高22.53(95%CI为19.52-25.54),P<0.001。
你好,请问方差不齐中的样本量一致性指的是小组之间还是大组之间的样本量呢?我要做2×2的交互作用分析,两个大组的样本量是172和169,四个小组的样本量是85,87,84和85,这样的样本分布算样本量一致嘛?
请问无法生成三个新变量,显示A program error has occurred: 某个过程尝试向文件中添加的变量多于该过程为 OBINIT 调用提供的变量。 在对 OBPINI 的调用中检测到此错误。Please note the circumstances under which this error occurred, attempting to replicate it if possible, and then notify Technical Support.
此命令的执行停止。
请问怎么解决
老师请问源数据可以分享么
站主这个教程全网最详细!大三非理工类做统计全靠一篇文捞
讲的很明白,谢谢!!!
大佬666,不过有一些图片挂了,看不到内容,大佬能补一下吗?
谢谢提醒,之前迁移过服务器,可能有些数据出了问题,谢谢提醒,已更新
楼主图片又挂了。。。
一些图片显示不出来
谢谢,已更新