原本想网上找一个现成的2021最新中科院分区表,奈何找了许久都没有,于是想着用R语言爬Letpub,电脑开着爬了一个晚上还没有结束,原因是网站的反爬机制,只能在爬取过程中设置间隔等待。这是进哥第一次网络爬虫,很多技术方面都不熟练。以前看网络爬虫大多是python写的,于是乎,反正是学习,直接学python爬虫吧,直接爬中国科学院文献情报中心期刊分区表(http://www.fenqubiao.com/),貌似没有反爬机制。话不多说,开始:
项目简介
本项目是用于对中国科学院文献情报中心期刊分区表的一个基于Selenium的爬虫,爬取信息即为分区和三年平均影响因子。
运行指南
- pip安装依赖,同时安装
WebDriver - 账户信息(进哥用的苏大账号,需要保证ip与账号符合)
爬虫代码
import xlwt
import time
# selenium模块
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support.select import Select
# 读取信息
username = 'SZDX'
password = '37193'
driver = webdriver.Edge("D:\Program Files (x86)\python\msedgedriver.exe")
driver.get('http://www.fenqubiao.com/')
driver.find_element_by_xpath("//input[@id='Username']").send_keys(username)
driver.find_element_by_xpath("//input[@id='Password']").send_keys(password)
time.sleep(2)
driver.find_element_by_xpath("//input[@id='login_button']").click()
url = 'http://www.fenqubiao.com/Core/CategoryList.aspx'
driver.get(url)
typeCat=driver.find_element_by_xpath("//select[@id='ContentPlaceHolder1_dplCategory']")
Select(typeCat).select_by_index(8)
time.sleep(3)
driver.find_element_by_xpath("//input[@id='ContentPlaceHolder1_btnSearch']").click()
time.sleep(0.5)
writebook = xlwt.Workbook(encoding='utf-8')
writesheet = writebook.add_sheet('生物类')
writesheet.write(0,0, label = '序号')
writesheet.write(0,1, label = '刊名全称')
writesheet.write(0,2, label = 'Review')
writesheet.write(0,3, label = '分区2021')
writesheet.write(0,4, label = '3年平均IF')
index = 0
for page in range(0, 2):
eles = WebDriverWait(driver, 30).until(EC.presence_of_all_elements_located((By.XPATH, "//tbody/tr")))
for i in range(0, len(eles)):
index += 1
paper = driver.find_elements_by_xpath('//tbody/tr')[i].find_elements_by_xpath('./td')
writesheet.write(index, 0, label=paper[0].get_attribute("textContent"))
writesheet.write(index, 1, label=paper[1].get_attribute("textContent"))
writesheet.write(index, 2, label=paper[2].get_attribute("textContent"))
writesheet.write(index, 3, label=paper[3].get_attribute("textContent"))
writesheet.write(index, 4, label=paper[4].get_attribute("textContent"))
driver.find_element_by_link_text("下一页").click()
time.sleep(4)
writebook.save('D:/Result.xls')结果展示:
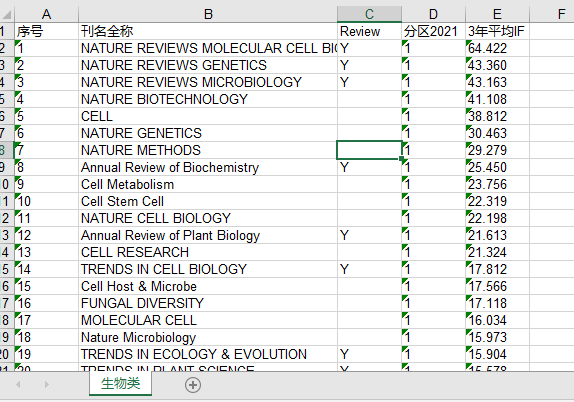
其它大类依次添加sheet爬取即可
PS:由于第一次玩,有些地方可能不太完善,还请各位大佬不吝赐教。