最近思考毕业论文题目,想着从国自然标书题目学习学习,查了一圈,还是letpub上比较方便,但是只有基本信息,没有摘要,也够了。于是写了一个R语言爬虫代码,基于RSelenium,有需要但不想自己下载的同学也可以留言。
不多说了,代码如下:
library(XML)
library(RSelenium)
library(rvest)
library(stringr)
library(data.table)
library(magrittr)
library(xlsx)
# Do not read string as a factor!
options(stringsAsFactors=F)
# load selenium service
system("java -jar E:/study/python/selenium-server-standalone-2.50.1.jar", wait=F, invisible=T, minimized=T)
# Configure the browser
eCap<- list(phantomjs.page.settings.userAgent="Mozilla/5.0 (Windows NT 6.1; WOW64; rv:29.0) Gecko/20120101 Firefox/29.0")
# remDr <- remoteDriver(browserName="chrome", extraCapabilities=eCap)
remDr <- remoteDriver(browserName="phantomjs", extraCapabilities=eCap)
# Open and parse the initial page
remDr$open()
remDr$navigate("https://www.letpub.com.cn/index.php?page=login")
opage <- remDr$getPageSource()[[1]] %>% read_html(encoding ="UTF-8") %>% htmlParse(encoding='UTF-8')
#显示出页面-----------------------------------------------------------------
# XML::htmlParse(remDr$getPageSource()[[1]])
remDr$maxWindowSize()
remDr$screenshot(display = TRUE)
#登录Letpub-----------------------------------------------------------------
btn_email<-remDr$findElement(using='xpath',value="//input[@id='email']")
btn_pass<-remDr$findElement(using='xpath',value="//input[@id='password']")
btn_login<-remDr$findElement(using='xpath',value="//img[@src='images/userlogin.jpg']")
username <- list('jin.wang93@outlook.com')
password <- list('930302Qq')
btn_email$sendKeysToElement(username)
btn_pass$sendKeysToElement(password)
btn_login$clickElement()
#打开基金搜索界面-----------------------------------------------------------------
remDr$navigate('http://www.letpub.com.cn/index.php?page=grant')
remDr$screenshot(display = TRUE)
Sys.sleep(1)
#输入关键词---------------------------------------------------------------------
keywords <- list('m6A 癌')
btn_key<-remDr$findElement(using='xpath',value="//input[@id='name']")
btn_key$sendKeysToElement(keywords)
#设置起始年限-------------------------------------------------------------------
btn_start<-remDr$findElement(using='xpath',value="//select[@id='startTime']/option[2]")
btn_start$clickElement()
#点击搜索---------------------------------------------------------------------
remDr$findElement(using='xpath',value="//input[@id='submit']")$clickElement()
Sys.sleep(2)
#提取表格---------------------------------------------------------------------
tpage <- remDr$getPageSource()[[1]] %>% read_html(encoding ="UTF-8") %>% htmlParse(encoding='UTF-8')
ttabl <- xpathSApply(tpage,"//table[@class='table_yjfx']")[[1]] %>% readHTMLTable(header=T) %>% set_colnames(.[1,]) %>% data.table() %>% .[c(-1,-.N),-7]
#获得总页数,letpub只允许显示20页,即只能检索200条信息,此处我没有添加这个判断函数,可以自行显示界面看一下;如果结果太多,建议修改关键词-----------------
mmm<-remDr$getPageSource()[[1]] %>%read_html(encoding ="UTF-8") %>% html_node('table.table_yjfx') %>% html_node('form') %>% html_text()
total_p<-strsplit(mmm,"/")[[1]][2]
total_p<-as.numeric(gsub('[页) ]',"",total_p))
#循环点击下一页提取表格---------------------------------------------------------------------
for (i in 1:(total_p-1)) {
next.btn <- remDr$findElement("link text", "下一页")
next.btn$clickElement()
#等待几秒页面刷新---------------------------------------------------------------------
Sys.sleep(2)
tpage <- remDr$getPageSource()[[1]] %>% read_html(encoding ="UTF-8") %>% htmlParse(encoding='UTF-8')
ttabl1 <- xpathSApply(tpage,"//table[@class='table_yjfx']")[[1]] %>% readHTMLTable(header=T) %>% set_colnames(.[1,]) %>% data.table() %>% .[c(-1,-.N),-7]
ttabl<-rbind(ttabl,ttabl1)
}
#整理表格---------------------------------------------------------------------
ttabl<-ttabl[-which( ttabl$负责人 %in% c("学科代码","执行时间")),]
tab_name<-ttabl[which(ttabl$项目编号!= "NA"), ]
tab_title<-ttabl[which(ttabl$负责人== "题目"), ][,2]
names(tab_title)<-c("题目")
tab_cat<-ttabl[which(ttabl$负责人== "学科分类"), ][,2]
names(tab_cat)<-c("学科分类")
table_final<-cbind(tab_name,tab_title)
table_final<-cbind(table_final,tab_cat)
#保存表格---------------------------------------------------------------------
write.csv(table_final, paste0('E:/LenovoBox/Letpub_grand/',as.character(keywords),'.csv'), row.names=F)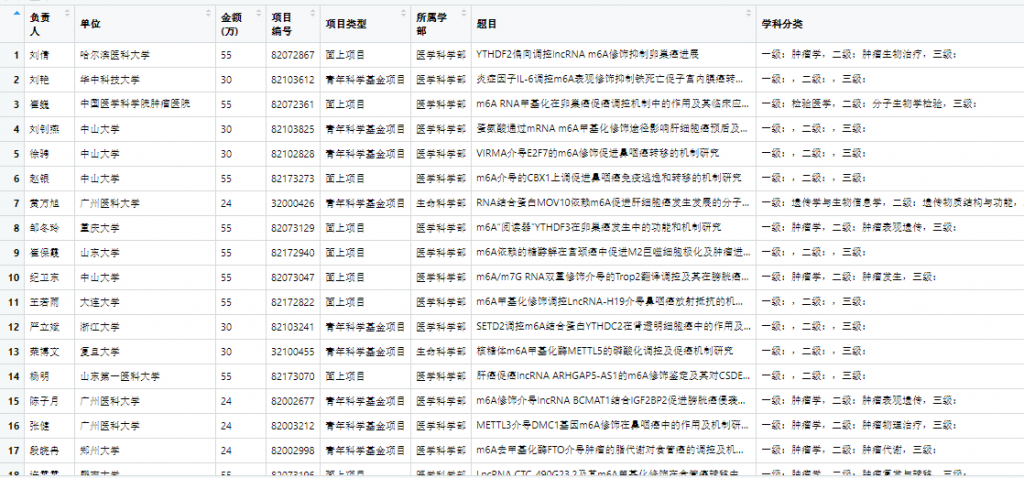
王老师,您好。能麻烦您帮我爬取一下地球科学部2021,2022,2023年的基金本子吗?因为需要进行相关内容的统计,能否帮忙用爬虫总结一下,非常感谢您!
王博士,您好。本人因为最近在些毕业论文,想要一些这个网址中的2019年审批的国家自然基金的项目医学事业部的信息,但我本人不会R语言,自己摆弄了一天,没成功,能否帮忙总结一些给我,谢谢!!!
eCap<- list(phantomjs.page.settings.userAgent="Mozilla/5.0 (Windows NT 6.1; WOW64; rv:29.0) Gecko/20120101 Firefox/29.0")
这句是啥意思呀,我配置浏览器不成功
爬虫这个我也只做过这几个,也不是很了解。这个就是爬虫需要设置的User-Agent
你好,王老师,你这个表格能分享下吗?
没有问题,您是要什么研究方向的?我这个检索的是m6A 癌为关键词,最近我想办法做个小工具可以挖掘国自然信息
王博士,您好。本人想要近三年有关大豆的国基金本子,作为本人写基金的参考。本人不是太会R语言,能否帮忙用爬虫总结一些给我,谢谢。
好的,没有问题,晚上把结果发您邮箱,但是爬的结果只有标题类型和自助金额等简单信息,没有全文和摘要,这些好像这两年都不公开