compareGroups 包
方便的统计汇总
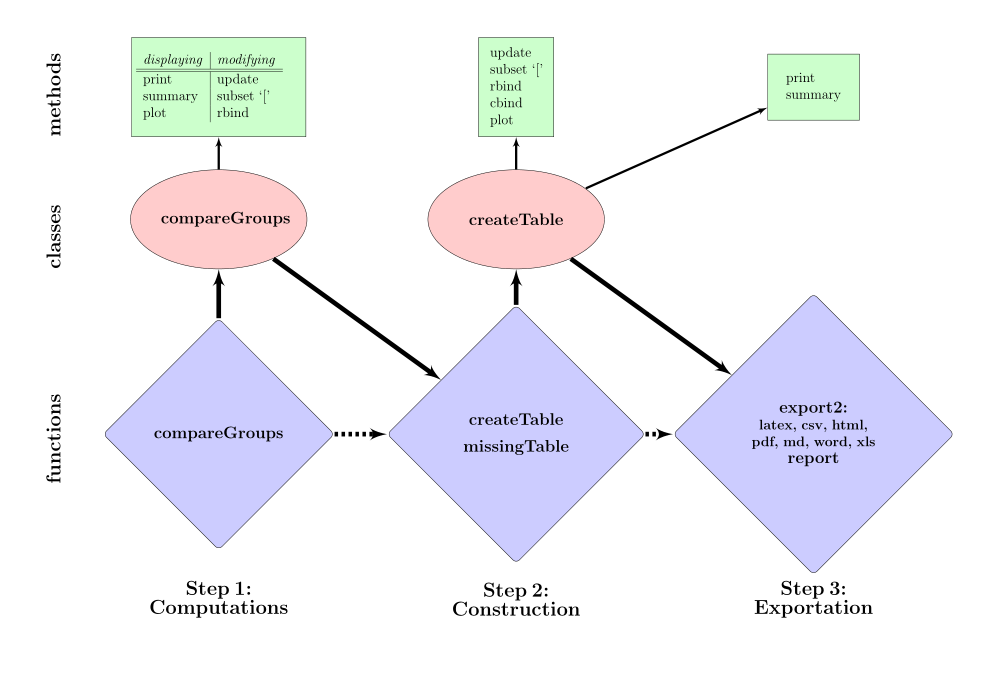
image.png
示例数据:
PREDIMED研究,针对高心血管风险患者饮食脂质的多中心研究,the PREDIMED study
数据预处理
data(predimed)
# 将生存数据整合放入
predimed$tmain <- with(predimed, Surv(toevent, event == "Yes"))
attr(predimed$tmain, "label") <- "AMI, stroke, or CV Death"将所有要分析的数据放进数据框,尽量不要有无用数据
流程
1. 计算统计描述:compareGroups
1.1 Usage:
compareGroups(formula, data, subset, na.action = NULL, y = NULL, Xext = NULL,
selec = NA, method = 1, timemax = NA, alpha = 0.05, min.dis = 5, max.ylev = 5,
max.xlev = 10, include.label = TRUE, Q1 = 0.25, Q3 = 0.75, simplify = TRUE,
ref = 1, ref.no = NA, fact.ratio = 1, ref.y = 1, p.corrected = TRUE,
compute.ratio = TRUE, include.miss = FALSE, oddsratio.method = "midp",
chisq.test.perm = FALSE, byrow = FALSE, chisq.test.B = 2000, chisq.test.seed = NULL,
Date.format = "d-mon-Y", var.equal = TRUE, conf.level = 0.95, surv=FALSE)1.2 重要参数说明:
- formula: .表示全部,-删去变量,例如:
group ~ . - toevent - event,公式可为空,或不含分组,则统计整体的统计描述 - subset:
subset = sex == "Female"对整个data起作用 - selec:
selec = list(hormo = sex == "Female", waist = waist > 20)对某个变量起作用的筛选- 公式中可以出现多次重复变量,对应可有多个变量筛选,例如:
compareGroups(group ~ age + sex + bmi + bmi + waist + hormo, data = predimed, selec = list(bmi.1 = !is.na(hormo)))
bmi.1对应第二次出现的bmi
- 公式中可以出现多次重复变量,对应可有多个变量筛选,例如:
- method:
默认所有的连续变量为正态分布,用ANOVA检验,可以定义具体变量,method=c(waist = 2)改变其分布,取值说明如下1:正态分布,ANOVA或t-test,多组间两两比较用Tukey2:非正态,Kruskal,BH校正3:分类,卡方或FisherNA:Shapiro-Wilks test 检测是否是正态分布,此外配合两个参数:alpha:决定Shapiro-Wilks检验的p值界值min.dis:当水平数少于此界值,转化为分类变量
- 注:当自变量为Surv对象时,用logrank检验
- max.ylev, max.xlev:分别规定分组变量与自变量水平数的最大值,
- include.label:如果数据框设置有变量label时,TRUE打印label,否则打印name
- Q1,Q3:当非正态分布时,设定显示的分位值,默认上下四分位数
- simplify:默认TRUE,删除空的因子水平,为FALSE时无法计算P值
- ref, ref.no:当分组变量为二分类时,可以计算OR,为time-to-event的Surv时,可以计算HR,均为单因素分析
- ref定义参照分类水平,用1,2,3,…表示,默认为1,也可定义部分变量,如
ref=c(smoke=2) - ref.no:定义自变量中因子水平相同的水平为参照水平,不区分大小写,在所有分类变量中找同名水平
- ref.y:计算OR时,分组变量的参照水平,默认为1
- ref定义参照分类水平,用1,2,3,…表示,默认为1,也可定义部分变量,如
- fact.ratio:对于连续变量,定义增加单位,例如
fact.ratio=c(bmi=2),表示bmi每增加2的OR - timemax:当自变量有Surv对象时,统计描述为中位随访时间的发生率,timemax设定描述的随访时间点,
timemax=c(tmain=3) - include.miss: 默认FALSE,TRUE时将缺失值归为”Missing”水平进行统计描述
1.3 compareGroups对象的summary
返回一个列表包含每个自变量显示详细的统计量:包括p.trend,p.overall,两两比较的P值
>res <- compareGroups(group ~ age + sex + smoke + waist + hormo,
method = c(waist = 2), data = predimed)
>summary(res[c(2)])
row-variable: Sex
Male Female Male (row%) Female (row%) p.overall p.trend p.Control vs MedDiet + Nuts p.Control vs MedDiet + VOO
[ALL] 2679 3645 42.36243 57.63757
Control 812 1230 39.76494 60.23506 8.1e-05 0.388386 0.000133 0.358324
MedDiet + Nuts 968 1132 46.09524 53.90476
MedDiet + VOO 899 1283 41.20073 58.79927
p.MedDiet + Nuts vs MedDiet + VOO
[ALL]
Control 0.002076
MedDiet + Nuts
MedDiet + VOO 1.4 compareGroups对象的plot
对具体变量可以绘图
Usage:
plot(x, file, type = "pdf", bivar = FALSE, z=1.5,
n.breaks = "Sturges", perc = FALSE, ...)bivar显示分组统计图,当分组变量为Surv时,分类变量为KM曲线,连续变量为标注结局的变量-时间散点图
1.5 compareGroups对象的update
usage:
res <- update(object=res, ...)参数同compareGroups
1.6 compareGroups对象的getResults
Usage:
getResults(obj, what = "descr")what可选: “descr”, “p.overall”, “p.trend”, “p.mul” and “ratio”,获取对应统计量
2. 创建统计表:createTable
2.1 Usage:
createTable(x, hide = NA, digits = NA, type = NA, show.p.overall = TRUE,
show.all, show.p.trend, show.p.mul = FALSE, show.n, show.ratio =
FALSE, show.descr = TRUE, show.ci = FALSE, hide.no = NA, digits.ratio = NA,
show.p.ratio = show.ratio, digits.p = 3, sd.type = 1, q.type = c(1, 1),
extra.labels = NA)该功能创建两个三线表,一个是统计汇总表,一个是统计方法概要表,
2.2 重要参数
- hide, hide.no:结果隐藏的变量,同ref,ref.no的变量设定,其中hide与ref不同的地方在于,hide可以以变量水平设定参考变量,而ref只能以水平索引,例如
update(restab, hide = c(sex = "Male")) - digits,digits.ratio: 统计描述的小数点,可以设定具体变量的小数点位数,例如
digits=c(age=2),digits.ratio显示OR或HR的小数点位数 - type: 分类变量的显示方式:1只显示百分数,3只显示频率,2与NA则都显示
- show.n:默认FALSE,TRUE时显示该变量统计时用到的样本量
- show.descr:默认TRUE,显示统计描述
- show.all:默认FALSE,TRUE显示总的统计量,添加’ALL’这一列,非常有用!!
- show.p.overall,show.p.trend,show.p.mul显示对应统计P值,show.ratio显示OR或HR
2.3 createTable的print
Usage:
print(x, which.table = "descr", nmax = TRUE, header.labels = c(), ...)which.table可取值’descr’, ‘avail’ or ‘both’,打印对应的统计表header.labels更改显示的列名,可以更改:all’, ‘p.overall’, ‘p.trend’, ‘ratio’, ‘p.ratio’ and ‘N’, 方式为header.labels=c(p.overall="p-value", all="ALL")nmax设定是否打印首行的样本量
>restab <- createTable(res)
>print(restab, which.table = "descr")
--------Summary descriptives table by 'Intervention group'---------
________________________________________________________________________________
Control MedDiet + Nuts MedDiet + VOO p.overall
N=2042 N=2100 N=2182
¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯
Age 67.3 (6.28) 66.7 (6.02) 67.0 (6.21) 0.003
Sex: <0.001
Male 812 (39.8%) 968 (46.1%) 899 (41.2%)
Female 1230 (60.2%) 1132 (53.9%) 1283 (58.8%)
.................
>print(restab, which.table = "avail")
---Available data----
________________________________________________________________________________________________________
[ALL] Control MedDiet + Nuts MedDiet + VOO method select
¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯
Age 6324 2042 2100 2182 continuous-normal ALL
Sex 6324 2042 2100 2182 categorical ALL
Hormone-replacement therapy 3459 1174 1066 1219 categorical sex == "Female"
.......................2.4 createTable的update
可以更新createTable, 同时也可更新compareGroups
示例:
update(restab, x = update(res, subset = c(sex == "Female")), show.n = TRUE)2.5 可以用的其它函数
- rbind,可以添加合并的标题:
restab1 <- createTable(compareGroups(group ~ age + sex, data = predimed))
restab2 <- createTable(compareGroups(group ~ bmi + smoke, data = predimed))
x=rbind(`Non-modifiable risk factors` = restab1, `Modifiable risk factors` = restab2)
# 选择部分变量
x[c(1,2,4)]- cbind,合并列,可以分层
res <- compareGroups(group ~ age + smoke + bmi + htn, data = predimed)
alltab <- createTable(res, show.p.overall = FALSE)
femaletab <- createTable(update(res, subset = sex == "Female"), show.p.overall = FALSE)
maletab <- createTable(update(res, subset = sex == "Male"), show.p.overall = FALSE)
# 合并
cbind(ALL = alltab, FEMALE = femaletab, MALE = maletab)
## caption参数定义每个层的标题- strataTable,快速按变量分层
# usage:
strataTable(x, strata, strata.names = NULL, max.nlevels = 5)
# 示例
strataTable(restab, "sex")2.6 一步构建表格:descrTable
Usage:
descrTable(formula, data, subset, na.action = NULL, y = NULL, Xext = NULL,
selec = NA, method = 1, timemax = NA, alpha = 0.05, min.dis = 5, max.ylev = 5,
max.xlev = 10, include.label = TRUE, Q1 = 0.25, Q3 = 0.75, simplify = TRUE,
ref = 1, ref.no = NA, fact.ratio = 1, ref.y = 1, p.corrected = TRUE,
compute.ratio = TRUE, include.miss = FALSE, oddsratio.method = "midp",
chisq.test.perm = FALSE, byrow = FALSE, chisq.test.B = 2000, chisq.test.seed = NULL,
Date.format = "d-mon-Y", var.equal = TRUE, conf.level = 0.95, surv = FALSE,
hide = NA, digits = NA, type = NA, show.p.overall = TRUE,
show.all, show.p.trend, show.p.mul = FALSE, show.n, show.ratio =
FALSE, show.descr = TRUE, show.ci = FALSE, hide.no = NA, digits.ratio = NA,
show.p.ratio = show.ratio, digits.p = 3, sd.type = 1, q.type = c(1, 1),
extra.labels = NA)参数同createTable和compareGroups
3. 导出
3.1 函数
- export2csv(restab, file=’table1.csv’)
- export2html(restab, file=’table1.html’)
- export2latex(restab, file=’table1.tex’)
- export2pdf(restab, file=’table1.pdf’)
- export2md(restab, file=’table1.md’)
- export2word(restab, file=’table1.docx’)
- export2xls(restab, file=’table1.xlsx’)
3.2 参数
- which.table:同上
- nmax:同上
- sep: csv
- 详细的参数见帮助文档
4. 缺失值处理
missingTable
missingTable(obj,...)obj可以是’compareGroups’ or ‘createTable’ object,统计每个行变量的缺失在分组变量的情况
图形界面分析
cGroupsGUI(predimed)触发,详见说明文档,需要安装“tcltk2”包
Shiny应用
cGroupsWUI(),详见说明文档,需要安装“shinyBS”包