library(survival)
library(rms)
library(pec)#计算时间c-index用
#清理工作环境
rm(list = ls())
#加载数据
,我随意加载的一组表达数据
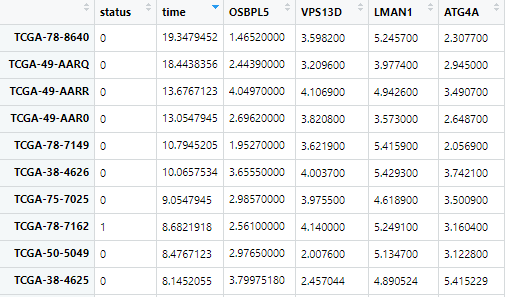
aa<-read.delim("Risk.txt",sep = "\t", row.names=1)
aa<-aa[1:6]
model1<-cph(Surv(time,status)~OSBPL5,x=T,y=T,surv=T,data=aa)
model2<-cph(Surv(time,status)~VPS13D,x=T,y=T,surv=T,data=aa)
model3<-cph(Surv(time,status)~LMAN1,x=T,y=T,surv=T,data=aa)
model4<-cph(Surv(time,status)~ATG4A,x=T,y=T,surv=T,data=aa)
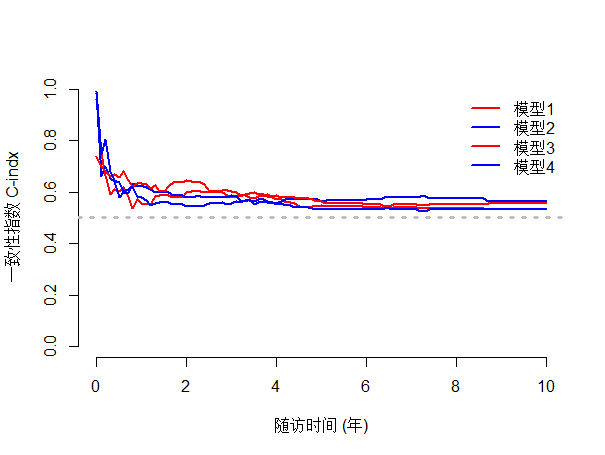
#pec包的cindex()可计算多个模型在多个时间点的C指数
pk<- cindex(list("模型1"=model1,
"模型2"=model2,
"模型3"=model3,
"模型4"=model4),
formula=Surv(time,status)~1,
data=aa,
eval.times=seq(0,10,0.1))
#绘制时间C-index
plot(pk,
col=c( "red", "blue","green","orange"),#曲线颜色
xlab="随访时间 (年)",#xy名字
ylab="一致性指数 C-indx",
ylim = c(0.5,0.7),#xy轴范围
xlim = c(0,10),
legend.x=8, #图例位置
legend.y=1,
legend.cex=1 #图例字号
)
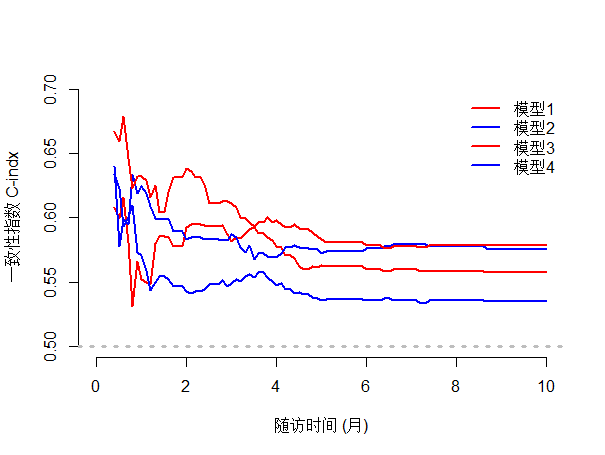
##校准后的时间C-index
pk2<- cindex(list("模型1"=model1,
"模型2"=model2,
"模型3"=model3,
"模型4"=model4),
formula=Surv(time,status)~1,
data=aa,
eval.times=seq(0,10,0.1),
splitMethod="Bootcv",#采用重抽样方法
B=1000) #B表示重抽样次数
plot(pk2,
col=c( "red", "blue","green","orange"),
xlab="随访时间 (月)",
ylab="一致性指数 C-indx",
ylim = c(0.5,0.7),
xlim = c(0,10),
legend.x=1,
legend.y=0.6,
legend.cex=1
)
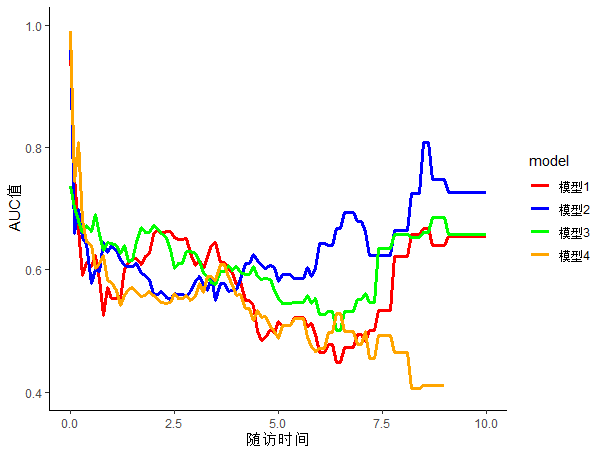
library(riskRegression)
#计算时间AUC
pk3<- Score(list("模型1"=model1,
"模型2"=model2,
"模型3"=model3,
"模型4"=model4),
formula=Surv(time,status)~1,
data=aa,
metrics="auc",
null.model=F,
times=seq(0,10,0.1))
auc<-plotAUC(pk3)
#美化、绘图
library(ggplot2)
cols <- c( "red", "blue","green","orange")
p<-ggplot(data=auc,
aes(x=times,
y=AUC,
color=model)) +
geom_line(size=1.2)+
theme_classic()+
ylim(0.4,1)+
labs(x="随访时间", y="AUC值")+
scale_colour_manual(values = cols)
p