有同学发邮件问我这个问题,我以前还真没有留意过,也是由于我这方面也是刚刚接触,对统计也是不甚了解,查阅资料终于知道了原因,下面一起来看看,学习一下:
相信大家在看构建模型类文献的时候,经常看到有这么一段话,说我们的风险评分Riskscore等于基因的表达量与其系数的乘积的加权。可是轮到自己构建模型的时候,用R语言的predict()函数计算出来的Riskscore,却与放到excel中,手动将这些建模的基因与其系数相乘,然后将这些乘积加起来的结果,并不相等。这是为什么呢,本节将为您解开心中解惑:
首先,我们可以看到下面几篇文献中关于Riskscore的描述:
上面几篇文献有28分的,有十几分的,也有几分的,有甲基化的,也有circRNA、mRNA的,它们构建模型的风险评分都是 Riskscore = 基因1的表达量*系数1 + 基因2的表达量*系数2 + … + 基因n的表达量*系数n。

但是我们在做自己的文章的时候,当我们用多因素cox回归建好模型后,用下面的代码计算的Riskscore:
load(file = “multicox_Exp.Rdata”) #加载数据head(multicox_Exp)[1:5,1:5] #看一下数据

数据的行名为样本名,第一列为生存时间,第二列为生存状态,其余为建模的”基因”。下面用predict()函数计算风险评分
riskScore=predict(multiCox,type=”risk”,newdata=multicox_Exp) #predict函数计算风险评分riskScore<-as.data.frame(riskScore)View(riskScore) #可以打开看一下
predict函数计算的riskscore
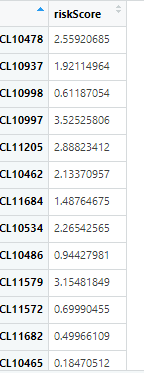
相信,接着,很多人都会再用建模的”基因“及其系数,在excel中计算一遍riskscore,用公式:
Riskscore = 基因1的表达量*系数1 + 基因2的表达量*系数2 + … + 基因n的表达量*系数n。得到
用excel计算的riskscore
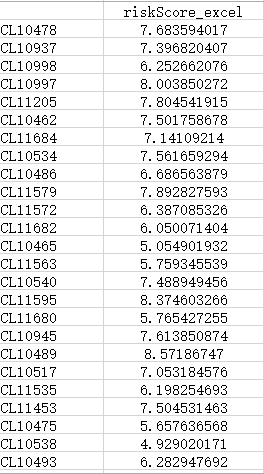
对比一下,很明显可以发现,对于同一个样本,其风险评分Riskscore,用predict()函数计算的,与用excel计算的并不相等。但很明确的是,咱们用excel计算Riskscore的时候,用的就是文献中所说的公式啊:基因的表达量与其系数的乘积的加权。这就说明了一个问题,多因素cox回归建模后,用predict()函数计算所得的Riskscore,并不是等于 基因1的表达量*系数1 + 基因2的表达量*系数2 + … + 基因n的表达量*系数n。那么,为什么文献中作者是这么说的呢,难道作者们都错了吗?
首先,我们了解一下cox回归,Cox回归是由英国生物统计学家D.R.COX提出的一种半参数的比例风险模型,可以同时分析多种因素对生存时间影响的多变量生存分析方法,Cox回归公式为:
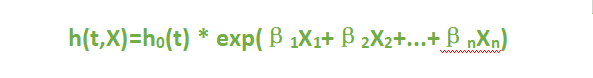
此公式中,β指回归系数,对其取反自然对数exp(β)后可以得到HR值;ho(t)为基准风险函数;h(t,X)为在时间t处与X(协变量)相关的风险函数。多因素cox回归建模后,我们用predict()函数计算得出的风险评分的值实际上是h(t,X), 而不是(β1X1 + β2X2 + …+βnXn) 。我们可以验证一下。
这里先说两个概念,比例风险假定和对数线性假定。比例风险假定是说各危险因素的作用不随时间的变化而变化,即h(t,X)/ho(t)不随时间的变化而变化,这一假定是建立cox回归的前提条件。对数线性假定是说cox回归模型中的协变量应与对数风险比呈线性相关。非常拗口,难以理解?
其实,从上述公式不难看出:
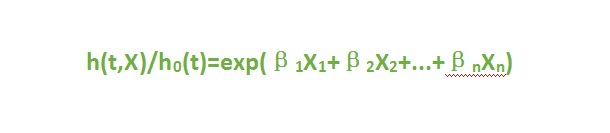
再取ln,得

结果如下:
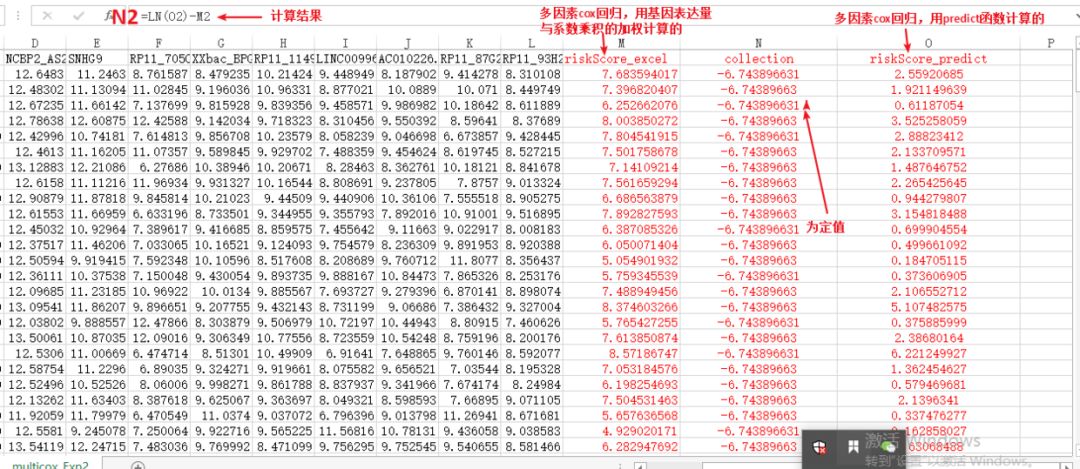
可以看到,计算结果collection这一列,几乎为一个定值(多了一个1的可能由于保留小数点后位数的不同所致)。其实collection这一列的计算结果就是 :lnho(t) 。
说到这,我想大家已经明白,如果我们用是多因素cox回归构建的模型,并且,用了函数predict()计算患者的风险评分,代码:
riskScore=predict(multiCox,type=”risk”,newdata=yourdata_Exp)
那么,我们在写论文的时候,就不能用开头的那几篇论文中的陈述方法来说表示我们的riskscore,而应该用
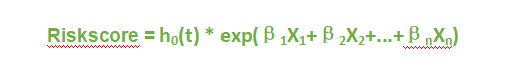
来描述我们构建的riskscore。
注意,上面咱说的是不能用陈述,是指不能用那个说法,毕竟我们明明用A方法计算的riskscore,却用B方法的描述方法来说A,这说法肯定不恰当吧。
那么,问题来了,假如我们用了多因素cox回归建模的,究竟可不可以用 基因1的表达量*系数1 + 基因2的表达量*系数2 + … + 基因n的表达量*系数n 来表示患者的riskscore呢? 嗯,可以的。上面可以看出,两种计算方式是呈对数线性关系的,这两种方法都是正确的。而且,
Riskscore = *基因1的表达量系数1 + 基因2的表达量*系数2 + … + 基因n的表达量*系数n 似乎是很多论文都喜欢采取的表示方式。所以如果我们在用多因素cox回归构建模型后,想用开头那几篇论文的这种方式(基因表达量与其系数的乘积的加权),那么,请记得手动excel中或者自己写个代码计算喔,而不是再用predict函数了喔。
转自:医学生之学习生信
可以出一个用excel算后 ROC与生存曲线吗