Nomogram,中文常称为诺莫图或者列线图。简单的说是将Logistic回归或Cox回归的结果进行可视化呈现。它根据所有自变量回归系数的大小来制定评分标准,给每个自变量的每个取值水平一个评分;对于每个患者,就可计算得到一个总分,再通过得分与结局发生概率之间的转换函数来计算每个患者的结局时间发生的概率。
1. 读图
随遍找一篇文章的图作为示例。
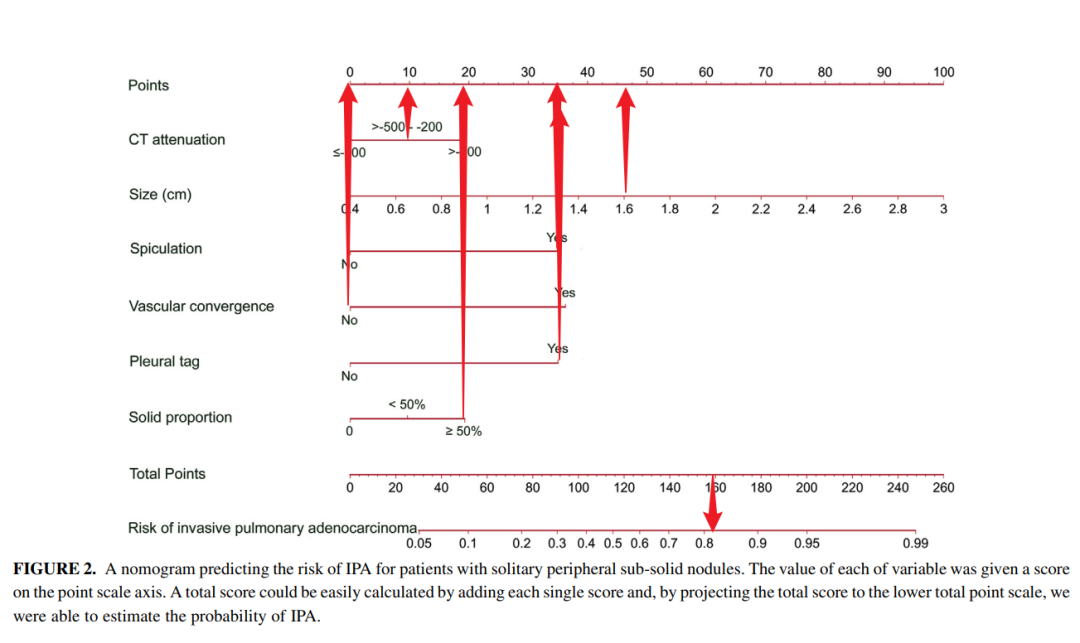
Jin C, Cao J, Cai Y, et al. A nomogram for predicting the risk of invasive pulmonary adenocarcinoma for patients with solitary peripheral subsolid nodules. J Thorac Cardiovasc Surg. 2017;153(2):462-469.e1.
红色箭头为我手动标注。
列线图的名称主要包括三个部分:
预测模型中的变量名称
例如图中的vascular convergence signs,pleural tag,computed tomography等信息,每一个变量对应的线段上都标注了刻度,代表了该变量的可取值范围,而线段的长度则反映了该因素对结局事件的贡献大小。
得分
- 单项得分,即图中的Points,表示每个变量在不同取值下所对应的单项分数,
- 总得分,即Total Point,表示所有变量取值后对应的单项分数加起来合计的总得分。
预测概率
例如图中的Risk of invasive pulmonary adenocarcinoma,表示侵袭性肺腺癌的患病风险。
如何计算呢?
如红色箭头所示,找出该患者每个变量对应的单项得分。最后将所有变量的单项得分相加,得到患者的总得分,并以总得分为基础,再向下画一条垂直线,就可以知道该患者侵袭性肺腺癌的患病风险。
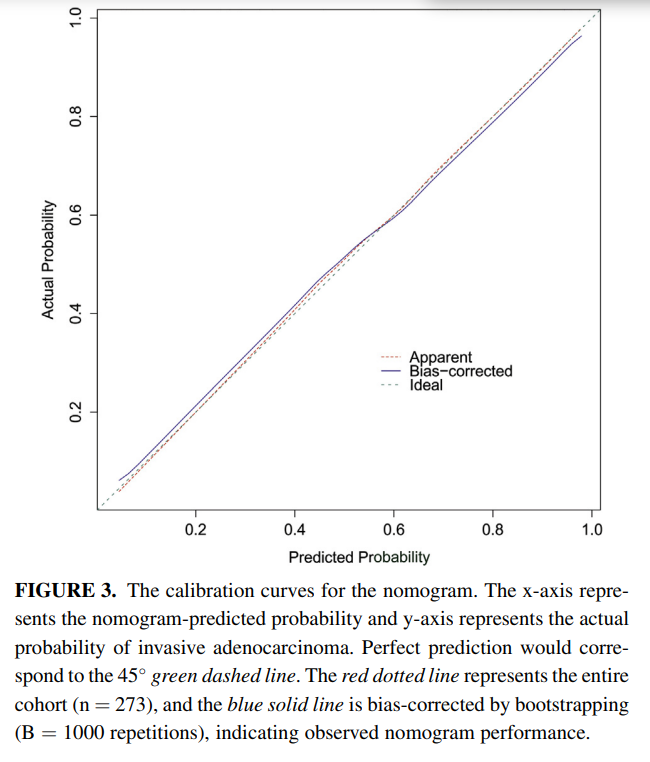
X轴表示诺模图预测的概率,y轴表示侵袭性腺癌的实际概率。完美的预测对应绿色虚线。红色虚线表示整个队列,蓝色实线通过Bootstrapping(1000次重复)进行偏差校正,表示观察到的诺模图性能。
分析并绘制
rm(list = ls())
library(survival)
library(survminer)
data(lung)
head(lung) #示例数据
## 添加变量标签
lung$sex <- factor(lung$sex,
levels = c(1,2),
labels = c("male", "female"))
head(lung)
## 根据nomogram要求处理数据
dd=datadist(lung)
options(datadist="dd")Logisitc回归模型
## 构建模型
## 构建logisitc回归模型,以age、sex为因子
f1 <- lrm(status~ age + sex, data = lung)
## 绘制logisitc回归的风险预测值的nomogram图
nom <- nomogram(f1, fun= function(x)1/(1+exp(-x)), # or fun=plogis
lp=F, funlabel="Risk")
plot(nom)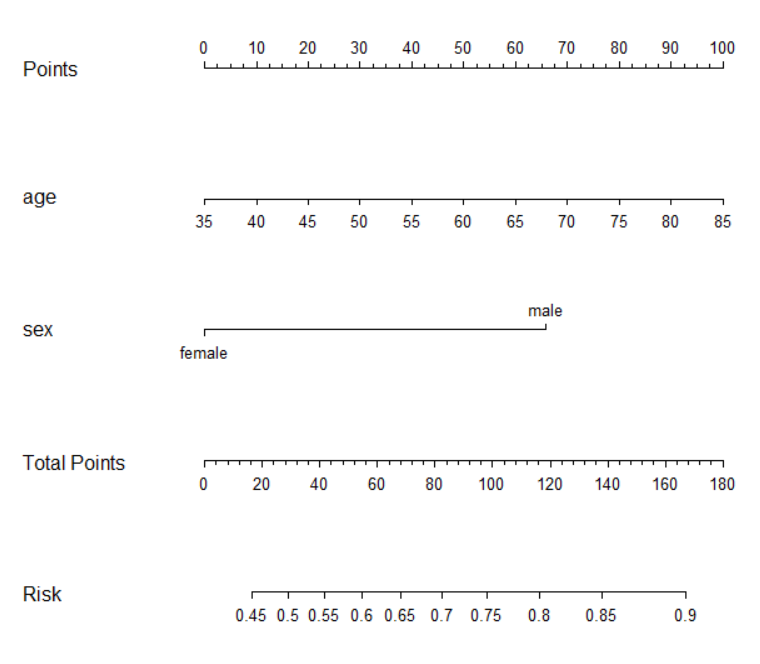
COX比例风险模型
f2 <- psm(Surv(time,status) ~ age+sex, data = lung, dist='lognormal')
med <- Quantile(f2) # 计算中位生存时间
surv <- Survival(f2) # 构建生存概率函数
## 绘制COX回归中位生存时间的Nomogram图
nom <- nomogram(f2, fun=function(x) med(lp=x),
funlabel="Median Survival Time")
plot(nom)
## 绘制COX回归生存概率的Nomogram图
## 注意lung数据的time是以’天‘为单位
nom <- nomogram(f2, fun=list(function(x) surv(365, x),
function(x) surv(730, x)),
funlabel=c("1-year Survival Probability",
"2-year Survival Probability"))
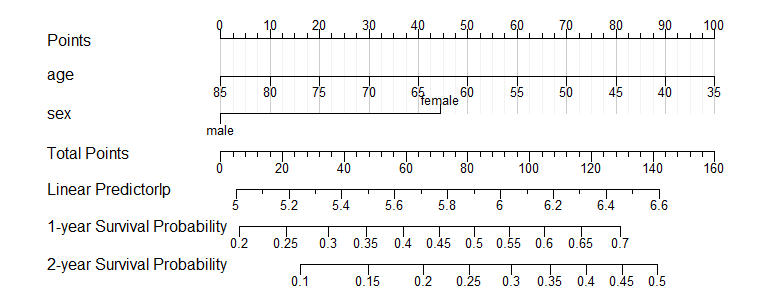
plot(nom, xfrac=.6)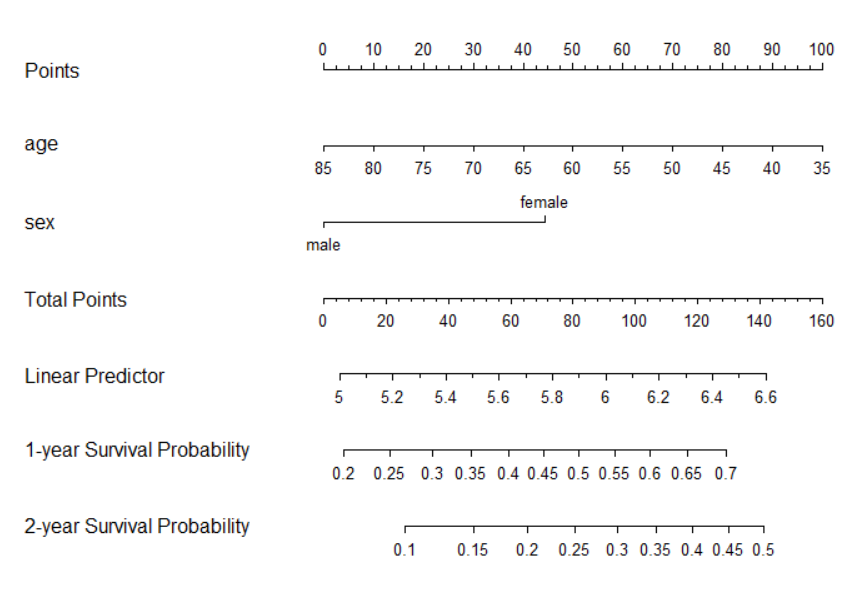
美化
plot(nomo2,
#1.变量与图形的占比
xfrac=.35,
#2.变量字体加粗
cex.var=1,
#3.数轴:字体的大小
cex.axis=0.8,
#4.数轴:刻度的长度
tcl=-0.5,
#5.数轴:文字与刻度的距离
lmgp=0.3,
#6.数轴:刻度下的文字,1=连续显示,2=隔一个显示一个
label.every=1,
#7.1个页面有几个数轴(这个可以压缩行间距)
naxes=13,
#8.垂直线的颜色.
col.grid=gray(c(0.8, 0.95)),
#9.线性预测轴名字
lplabel='Linear Predictorlp',
#10变量分数名字
points.label='Points',
#11总分名字
total.points.label='Total Points',
force.label=T#没啥用。TRUE强制标记的每个刻度线都绘制标签,我也没研究明白
)
## 评价COX回归的预测效果
## 计算c-index
rcorrcens(Surv(time,status) ~ predict(f2), data = lung)
Somers' Rank Correlation for Censored Data Response variable:Surv(time, status)
C Dxy aDxy SD Z P n
predict(f2) 0.601 0.203 0.203 0.051 3.98 1e-04 228
C-index,concordance index,一致性指数,主要用于计算生存分析中的COX模型预测值与真实之间的区分度,常用在评价患者预后模型的预测精度中。 C-index在0.5-1之间(任意配对随机情况下一致与不一致刚好是0.5的概率)。0.5为完全不一致,说明该模型没有预测作用,1为完全一致,说明该模型预测结果与实际完全一致。一般情况下C-index在0.50-0.70为准确度较低:在0.71-0.90之间为准确度中等;而高于0.90则为
Calibration校准曲线
## 绘制校正曲线
## 重新调整模型函数f2,也即添加x=T, y=T
f2 <- psm(Surv(time,status) ~ age+sex, data = lung, x=T, y=T, dist='lognormal')
## 构建校正曲线
cal1 <- calibrate(f2,
cmethod='KM',
method="boot",
u=365, # u需要与之前模型中定义好的time.inc一致,即365或730;
m=76, #每次抽样的样本量,
B=1000) #抽样次数
## m要根据样本量来确定,由于标准曲线一般将所有样本分为3组(在图中显示3个点)
## 绘制校正曲线
plot(cal1,lwd=2,lty=1,
conf.int=T,# 是否显示置信区间
errbar.col="blue",#直线曲线bar颜色
col="red", # 曲线颜色
xlim=c(0.25,0.6),ylim=c(0.15,0.70),
xlab="Nomogram-Predicted Probability of 1-Year DFS",
ylab="Actual 1-Year DFS (proportion)",
subtitles = F)#不显示副标题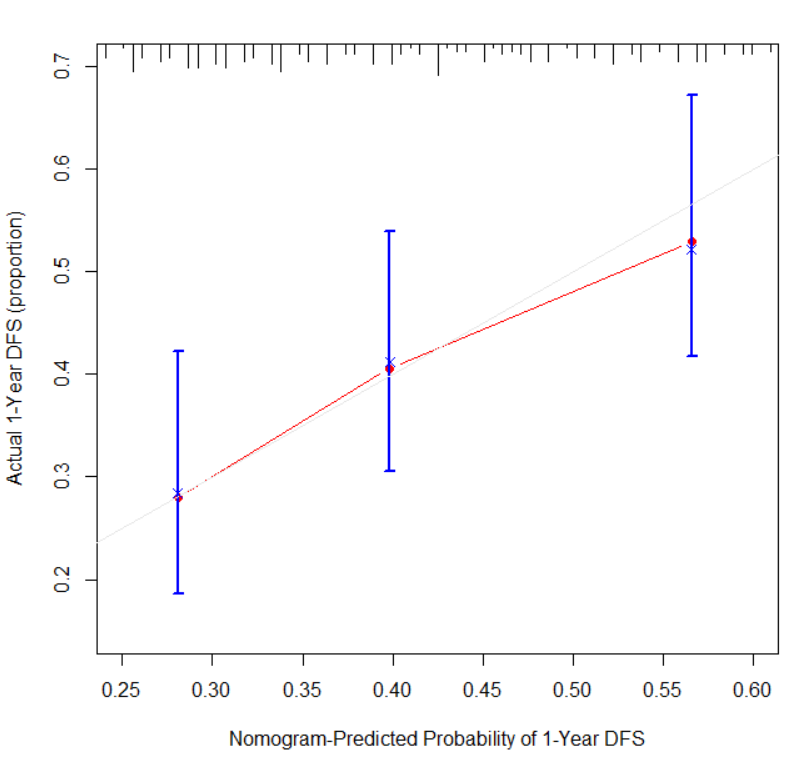
横坐标为预测的事件发生率(Predicted risk),纵坐标是观察到的实际事件发生率(Observed risk),范围均为0到1,可以理解为事件发生率(百分比)。对角线的虚线是参考线,即预测值=实际值的情况。红线是曲线拟合线,两边带颜色部分是95%CI。 • 如果预测值=观察值,则红线与参考线完全重合 • 如果预测值>观察值,即高估了风险,则红线在参考线下面 • 如果预测值<观察值,即低估了风险,则黑线在参考线上面 最理想的情况下, 校准曲线是一条对角线(预测概率等于经验概率),校准曲线不一定会单调递增, 比如, 当分桶的数量比较多时或者分类器比较弱时,通常情况下, Logistic Regression的校准曲线非常贴近于对角线,缺乏自信的模型的校准曲线是sigmoid形的。 校准曲线是一种评价模型的方法,在实际项目中应该是构建好模型,然后评价模型,改善模型,确定最终模型(C-index/ROC/DCA结果表明模型合格),最后对模型进行可视化展示(如森林图、列线图,生存点图等)。
Error in reformulate(attr(termobj, “term.labels”)[-dropx], response = if (keep.response) termobj[[2L]], :
‘termlabels’必需是长度至少为一的字节矢量,无论是lung数据集还是自己数据集构建诺莫图老报错
进哥哥,为什么在做校正曲线时一值说超出下标呢
请问lrm,cph,和psm的区别是什么,要如何选择呐?
为什么我的R抱错显示“Error in psm(Surv(futime, fustat) ~ Group, data = rt, x = T, y = T, dist = “lognormal”) :
could not find function “psm””,为什么不能发现psm函数呢?需要自己定义么
诶,需要加在rms包,library(rms)