一、CPTAC数据库功能介绍
和TCGA数据库一样,CPTAC数据库也是NIH的一个项目。其中主要提供了不同癌症类型的蛋白质组学数据,此外还包含基因组测序、miRNA测序和DNA甲基化数据等,是不是很棒,一下子可以做多个水平的多组学联合分析。其中基因组数据包含总计1300+不同类型肿瘤病人的WGS、WES和RNA-seq数据,可通过GDC Data Portal访问,也就是咱们下载TCGA数据库的界面。
蛋白组数据可通过PDC 访问(https://pdc.cancer.gov/pdc/browse),CPTAC数据库用到的蛋白质定量技术主要是基于质谱的检测技术,包括ITRAQ和TMT。
收集的信息如下:
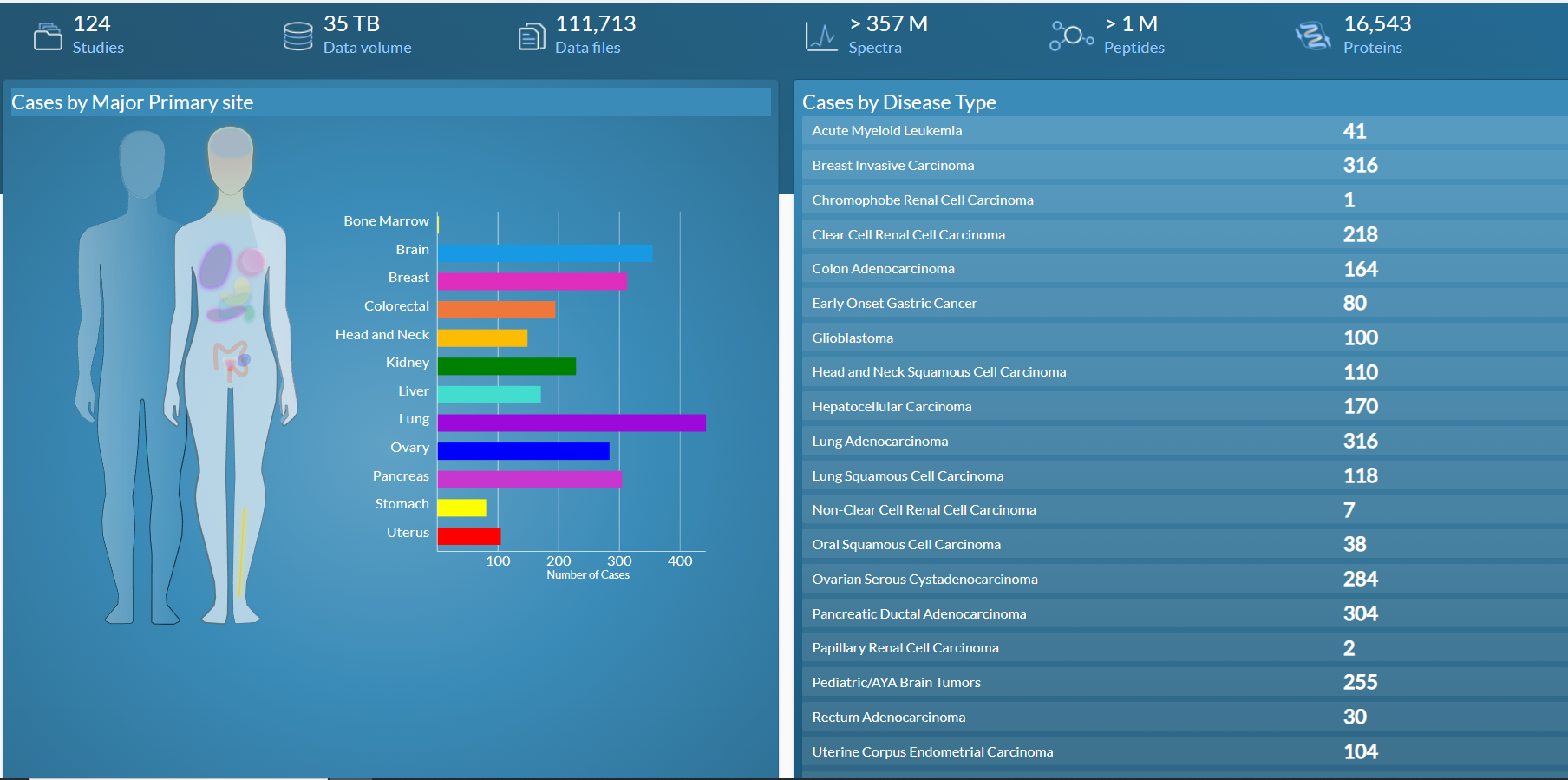
此外,CPTAC数据库还提供了生物样品的元数据和临床数据,例如病人的性别、年龄、癌症类型和临床治疗记录等。分析工具和生物信息学资源包括了一系列数据处理和分析工具等。CPTAC数据库的综合性质使其成为肿瘤分子分析的重要数据来源。
二、CPTAC数据库使用方法
1. 数据库访问
用可以通过网站(https://pdc.cancer.gov/pdc/browse)访问该数据库,下载过TCGA数据库的都应该很熟悉,基本差不多。
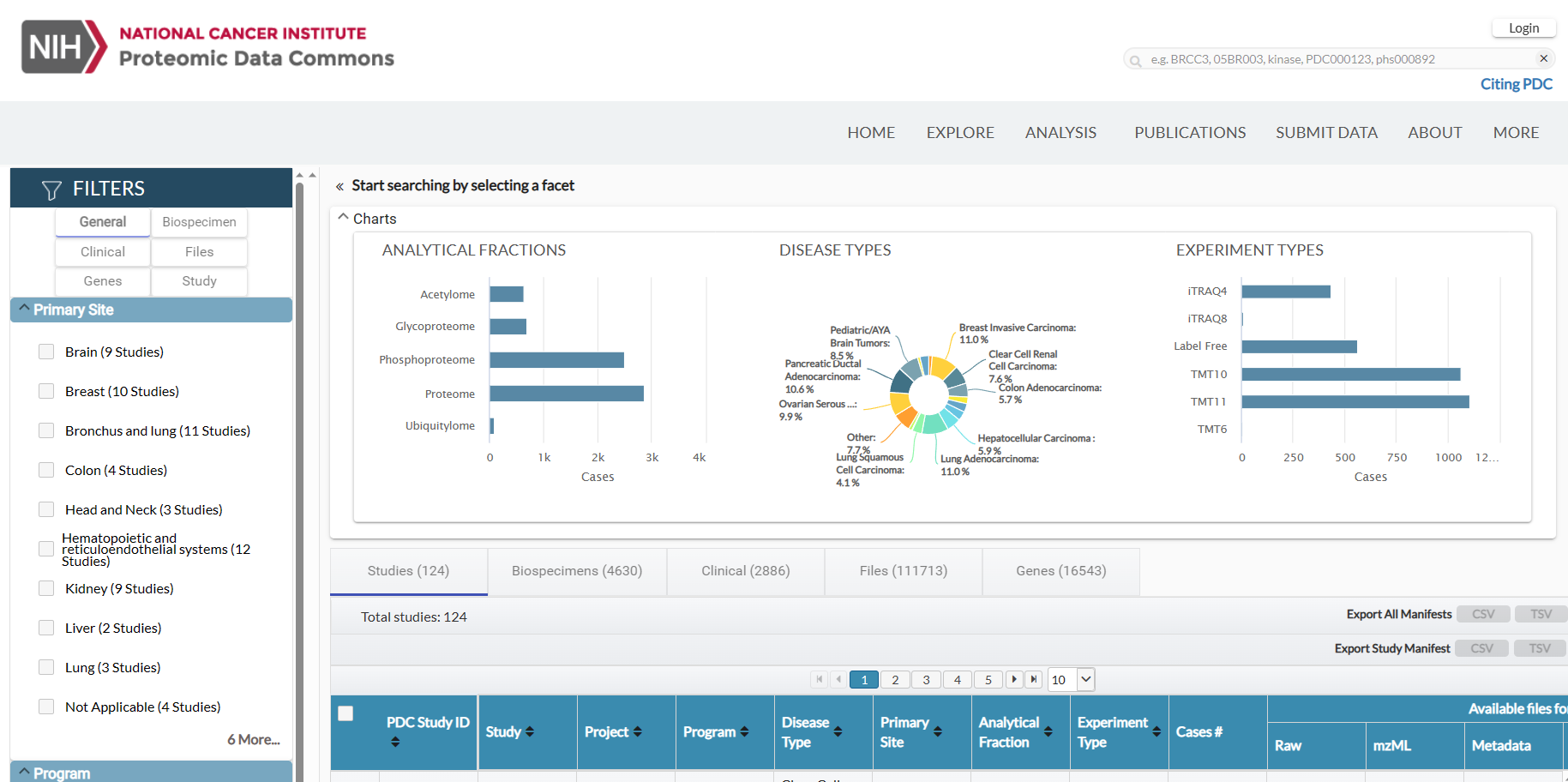
包含完善的统计信息和数据集信息,点击PDC Study ID查看详细信息:
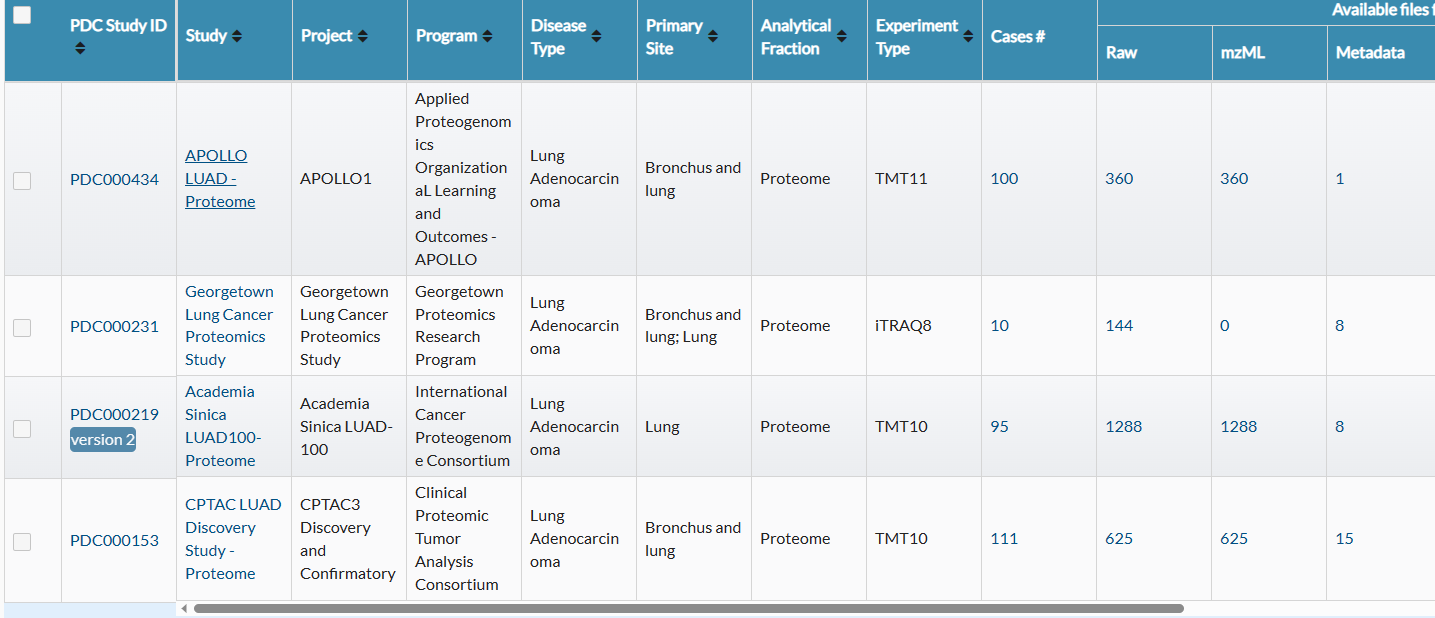
以CPTAC LUAD为例,点进去可以看到每个研究项目的详细信息:

如果需要下载原始数据信息点击Files下面的数字625,下载处理好整合好的数据点击6:
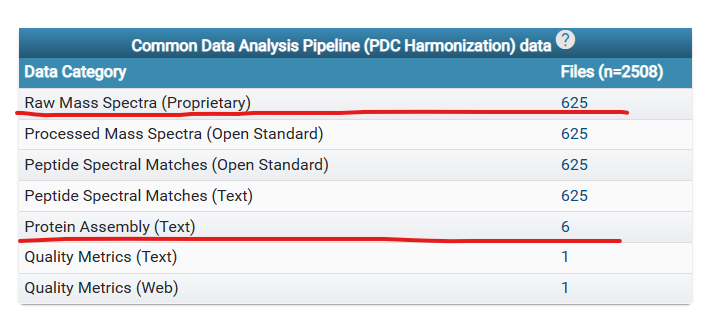
点击Protein assembly之后,如下图可以下载整合好的数据:
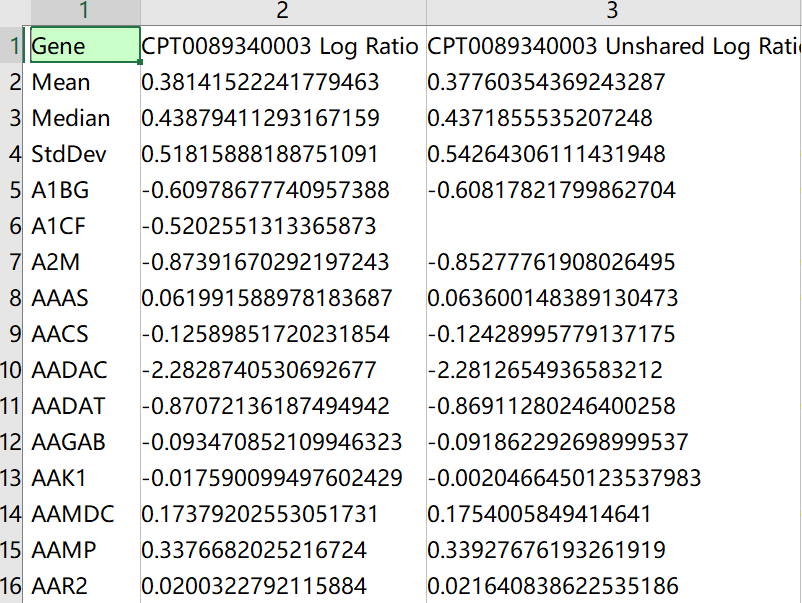
打开就可以看到咱们无比熟悉亲切的矩阵,需要注意的是数据中包含log Ratio 和Unshared log ratio,咱们只需要Unshared这个数据,需要用R语言提取一下。 然后就可以开心的进行分析了。
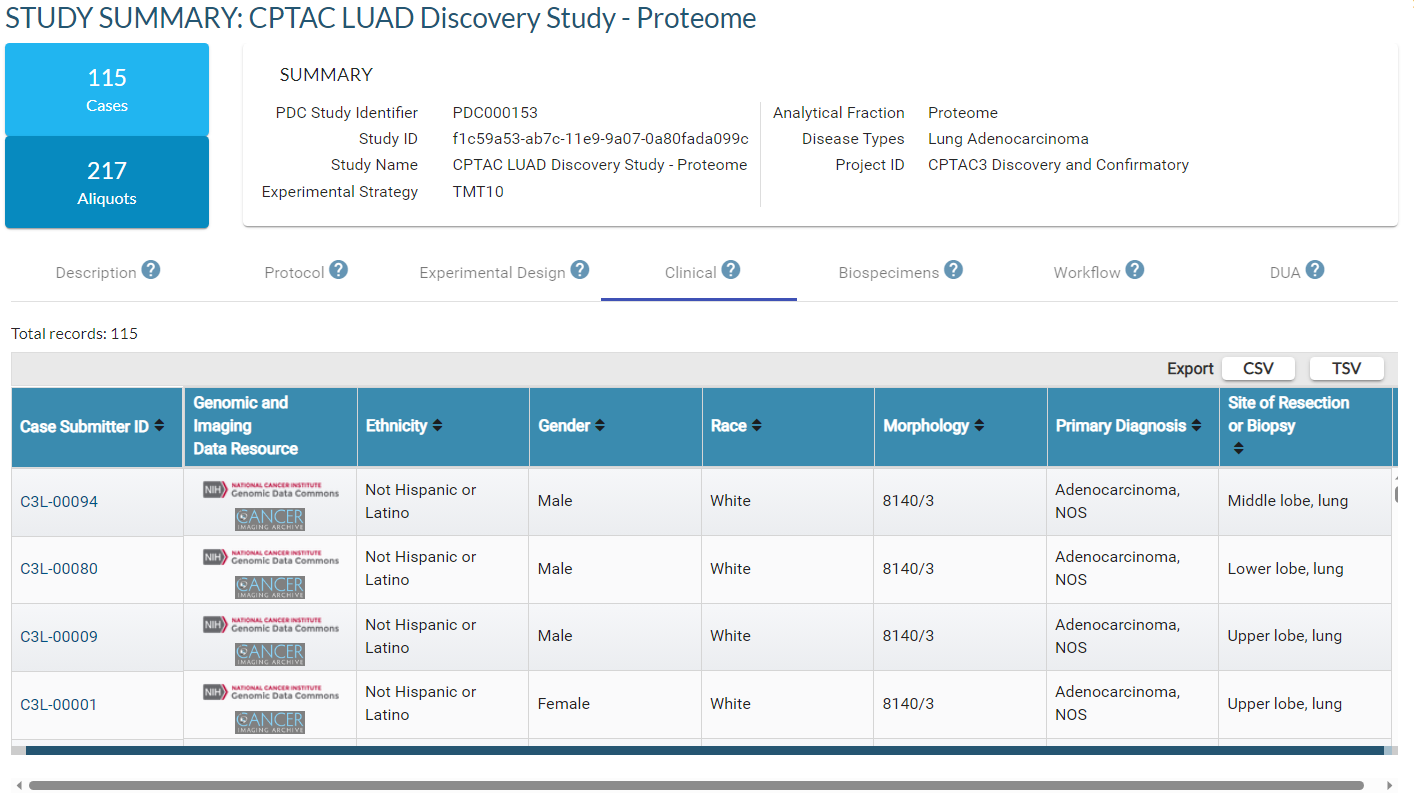
对于Clinical data,如下图可下载:
2. 分析工具
CPTAC数据库还提供了一些分析工具,方便用户对蛋白质组学数据进行可视化。

(1)Explore Quantitation Data
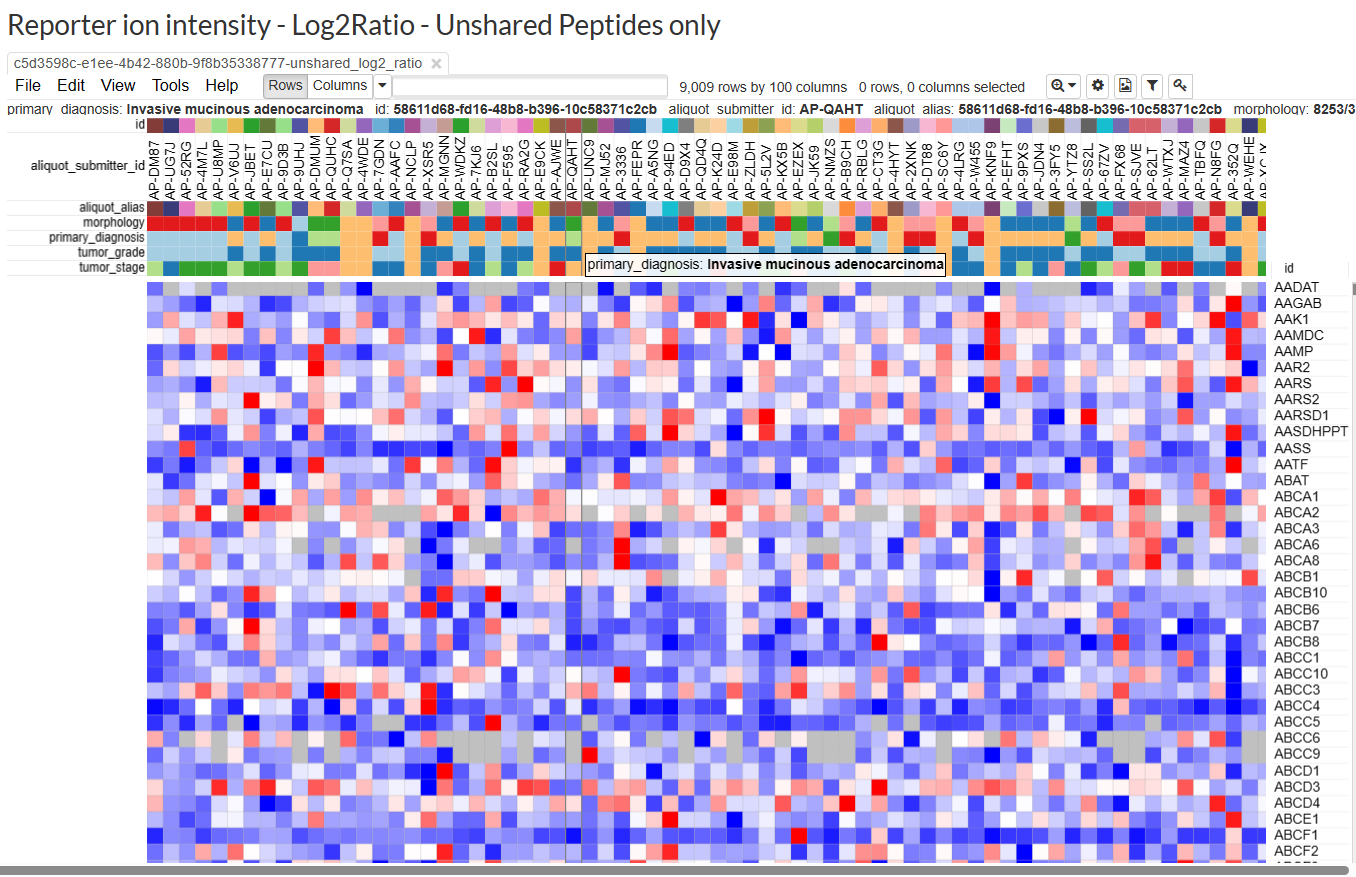
PDC通过标准分析流程产生结果后可用于鉴别蛋白质和翻译后修饰(PTMs)丰度的pattern,并通过热图展示。Explore Quantitation Data 可对每个study的蛋白定量结果进行分析和展示。其中行为基因(蛋白),列为样本,并可嵌入临床信息。可以调整很多参数,大家自行摸索。
(2)Peptide Genome mapping
主要是各种类型数据在基因组上的可视化展示。
(3)Pepquery
这是一个以肽段序列为中心的搜索,与Blast类似,Pepquery使用户能够在MS数据库中查询感兴趣的新的肽段或DNA序列。基因组改变导致产生新的蛋白序列,经过蛋白组学验证,这些新的序列可能会是潜在的疾病标志物或治疗靶标。Pepquery不需要定制化的构建数据库,区别于spectrum-centric的方法,使用peptide-centric,允许快速和方便的验证基因组改变导致的蛋白质组改变。
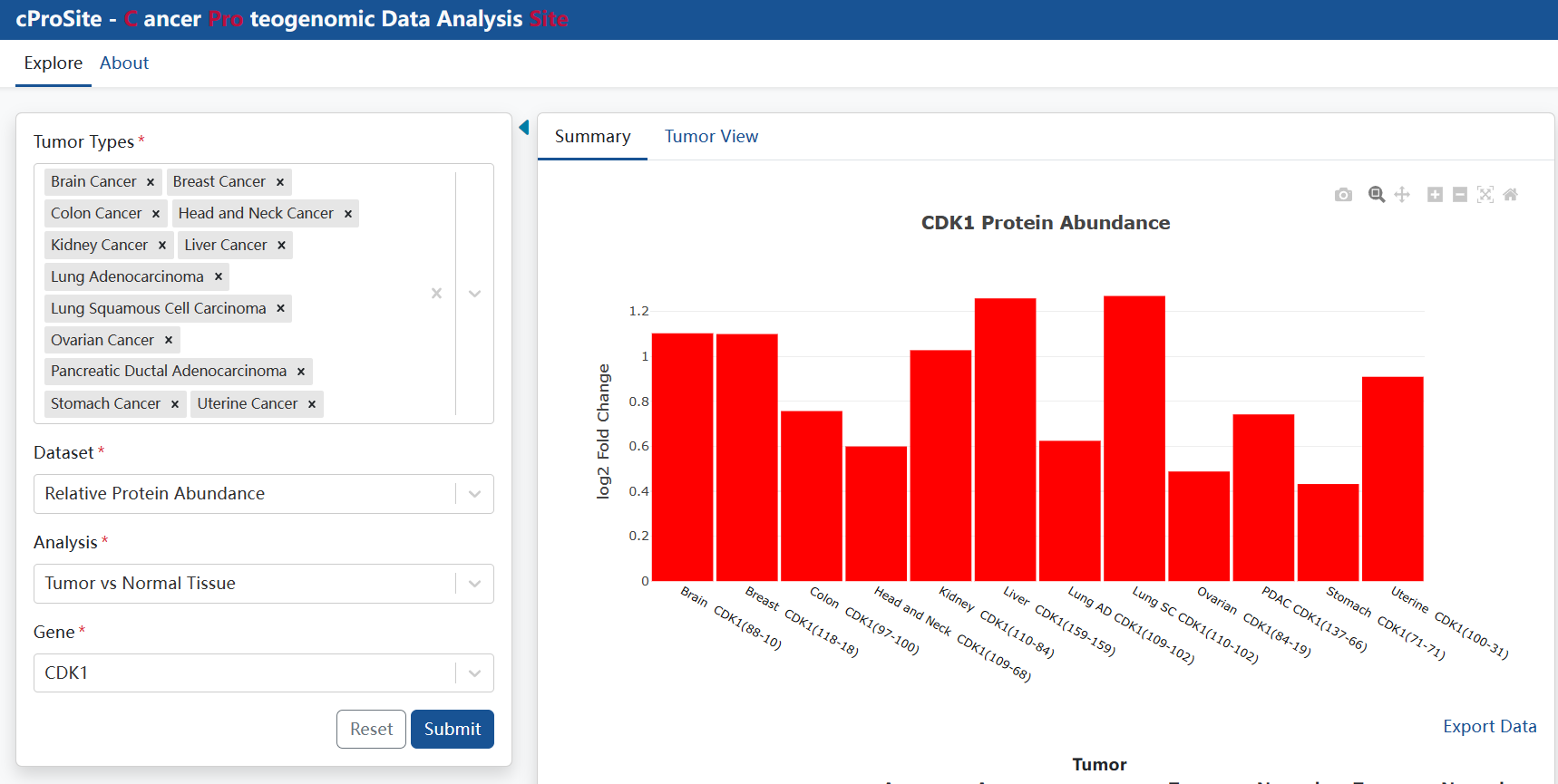
(4)cProSite
可指定肿瘤类型和数据集,针对单个基因,分析其在肿瘤和癌旁组织的丰度差异,磷酸化位点差异等。可用于验证目标基因是否在指定类型肿瘤中存在高表达,磷酸化等。也可以选择多种癌症类型进行泛癌分析:
我想请问一下如果是原始数据的话需要经过什么处理流程呢
请问下载数据里的缺失值补充是用的什么方法?
请问Unshared Log Ratio和Log Ratio处理的数据有什么不同呀, 我用两个数据跑出来的结果差距还挺大的
小程序可以提供整理后的数据下载吗,求求了
unshared数据有重复啊,每个病人有2个肿瘤和2个正常组织的数据,如何取舍呢??
师兄您好!关于数据处理,在您演示的LUAD数据中,即使只保留Unshared数据,我发现也有400多列,其中每个病人的肿瘤组织和正常组织均有2份数据,即每个患者有4份unshared数据,请问你是如何处理这个情况的呢?取平均值?还是单纯舍弃其中一份?
这个数据库包含临床信息中的肿瘤转移信息吗
关于我之前问的第3个问题,我发现是我漏掉了clinical data里面有对应的临床病理信息,也有对应的submitter id。
请问,
1. 从您编写的https://jingle.shinyapps.io/CPTAC/网站上下载了3个LUAD的数据集,不同数据集的蛋白表达水平是可比的吗?是有经过校正的吗?
2. 上述下载的3个LUAD的数据集,共包含的tumor有428例,但我自己从原文下载的附件中找到的tumor数目分别是89,100,110例,合计299例,为什么数据量会有差异呢?
3.上述下载的LUAD数据集的ID,如X469ded87.becc.11e9.9a07.0a80fada099c,这种如何跟原文附件中的ID匹配上,如C3L-00893?
您好,请问我下载的临床信息clinical manifest怎么和表达量信息匹配了?表达量文件里列名为id号,在临床信息里未找到对应的id号和其他匹配的信息
寻求CPTAC数据库基因差异分析和生存分析的R代码
这个只要数据有了 和TCGA差不多,我已经更新了这个文章,加了我做的数据下载的小程序