简介
本小程序基于R语言编写的Shiny app,用于GEO数据库大多数数据的整合和差异分析,以及火山图和热图绘制,操作简单,以下是app界面:
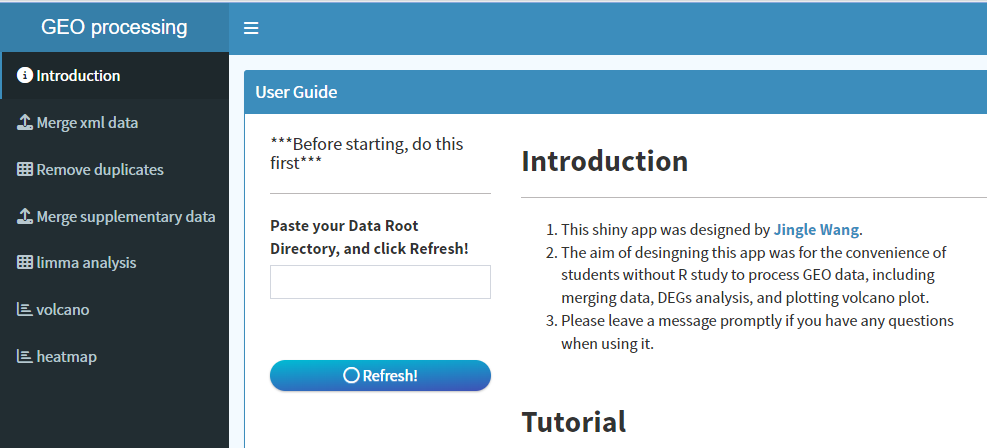
操作手册:
使用之前需要做的事情,打开ui.R文件,可见本小程序所需packages:
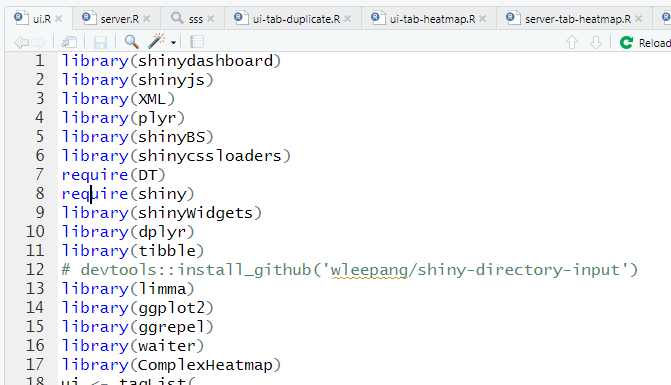
一般打开之后RStudio会提示安装包,如果没有安装全,请使用install.packages或BiocManager::install()进行安装。
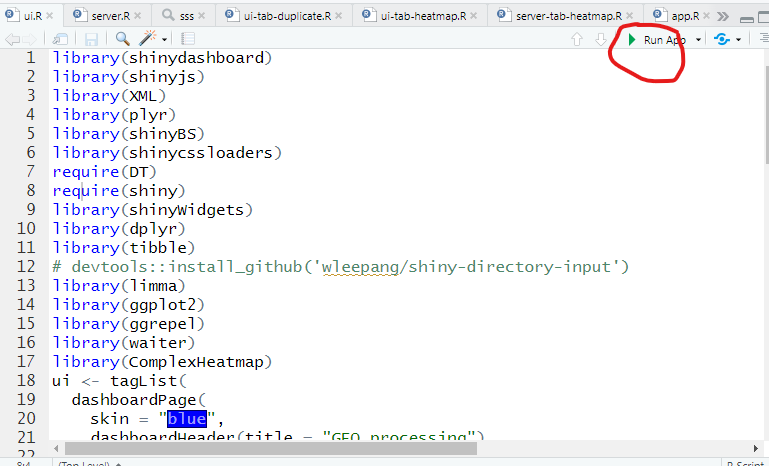
安装完成之后,点击代码窗口右上角:Run app,即可运行小程序,如有报错,应该是缺少相关包,退出安装即可。
一、芯片数据下载及分析
1. GEO数据库检索相关数据集,点进去之后往下拉,点击MINIML formatted family files,进入FTP下载界面,点击文件即可下载

2. ,保存到本地目录后解压
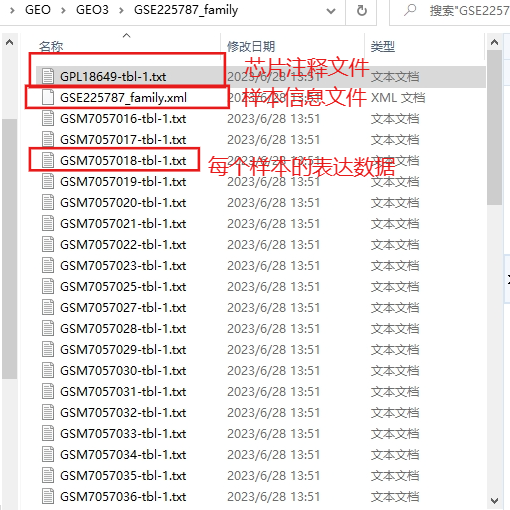
有三种类型数据:
GPL文件:用于ID转换
XML文件:存储样本信息
tbl-1文件:每个样本的表达数据
3. 复制文件夹路径:例如E:\post PhD study\哔哩哔哩·视频\基因筛选\GEO\GEO3\GSE225787_family,粘贴到小程序的Introduction界面文本框中:
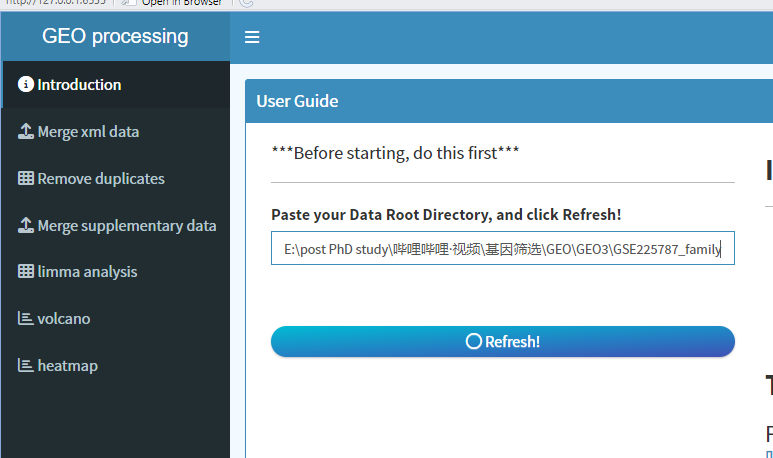
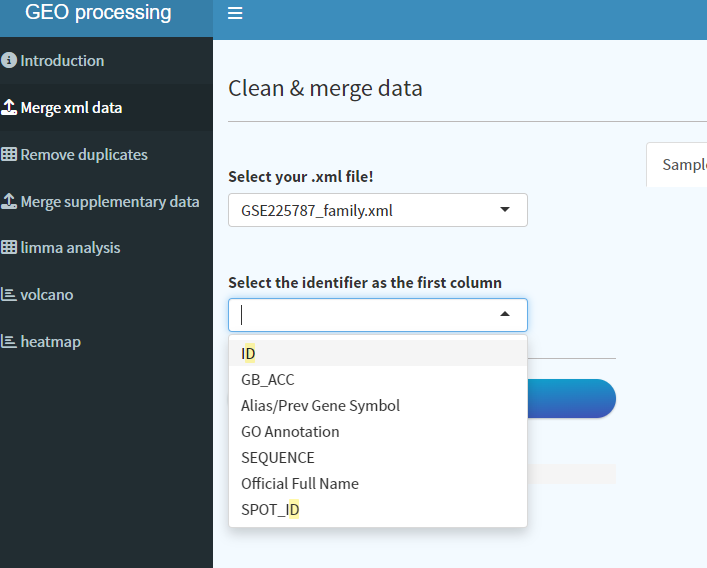
4. 点击Refresh,会自动获取这个路径下的所有文件,进入Merge xml data界面,此时第一个下拉框会自动填充xml文件,另一个下拉框可以选择需要显示的gene identifier,一般大家习惯用gene name/symbol。本案例中没有,我们选择GB_ACC,是accession id,可以后续转换。
5. 点击Submit,稍等片刻即可完成数据的整合以及样本信息的提取
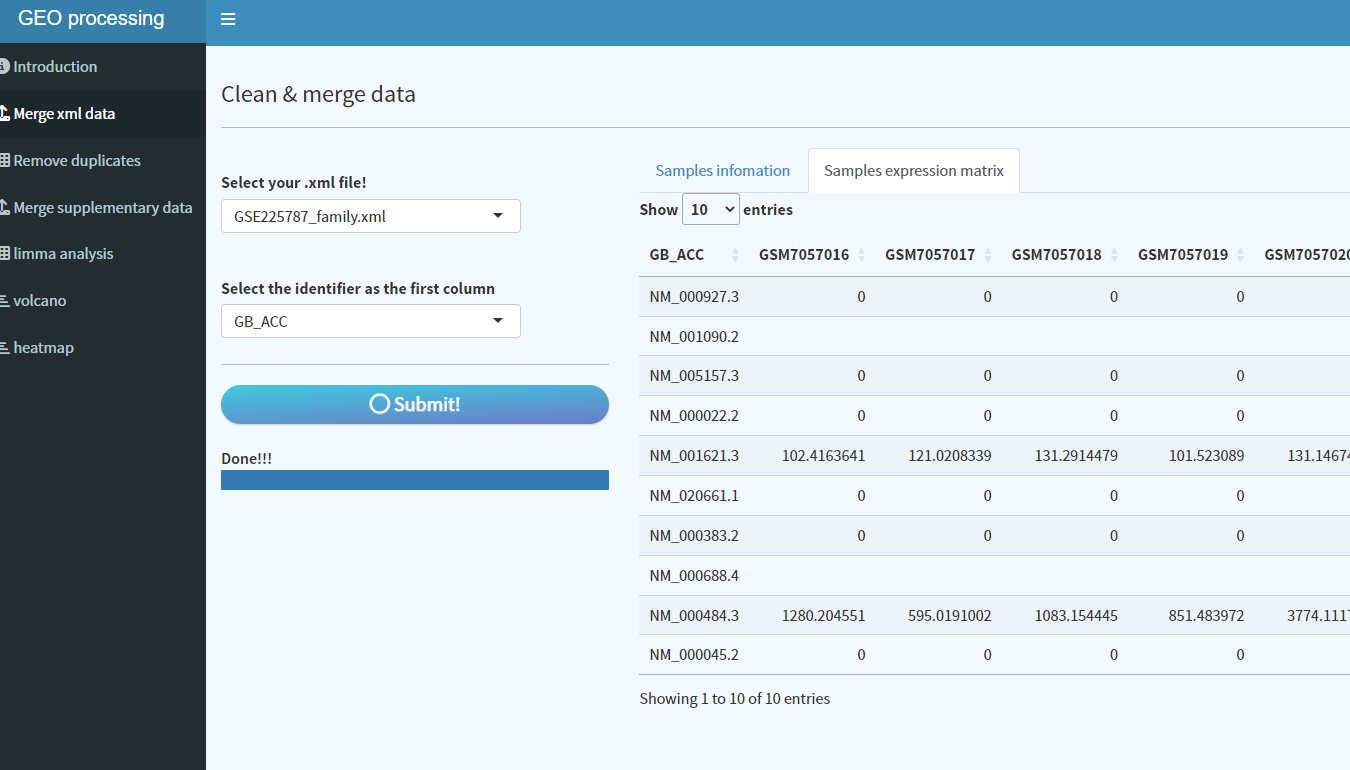
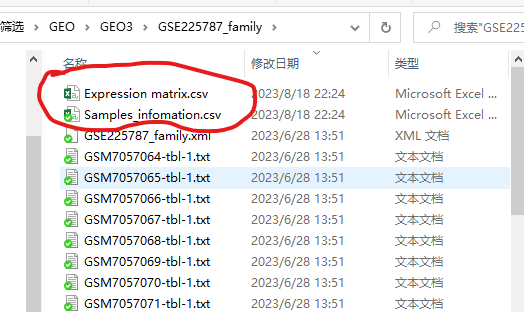
分析完成之后程序会自动保存样本信息及整合好的表达矩阵至设置的目录下:
6. 由于芯片通常存在一个基因对应多个探针的情况,因此需要对ID转换之后的数据进行基因名称去重处理,咱们设置了四种:max、min、median和mean。点击Get files|按钮,整合好的matrix文件自动填充,选择去重方法,点击Submit!
根据样本及基因量,去重时间不一,对于较大数据,请耐心等待,可能得几分钟。
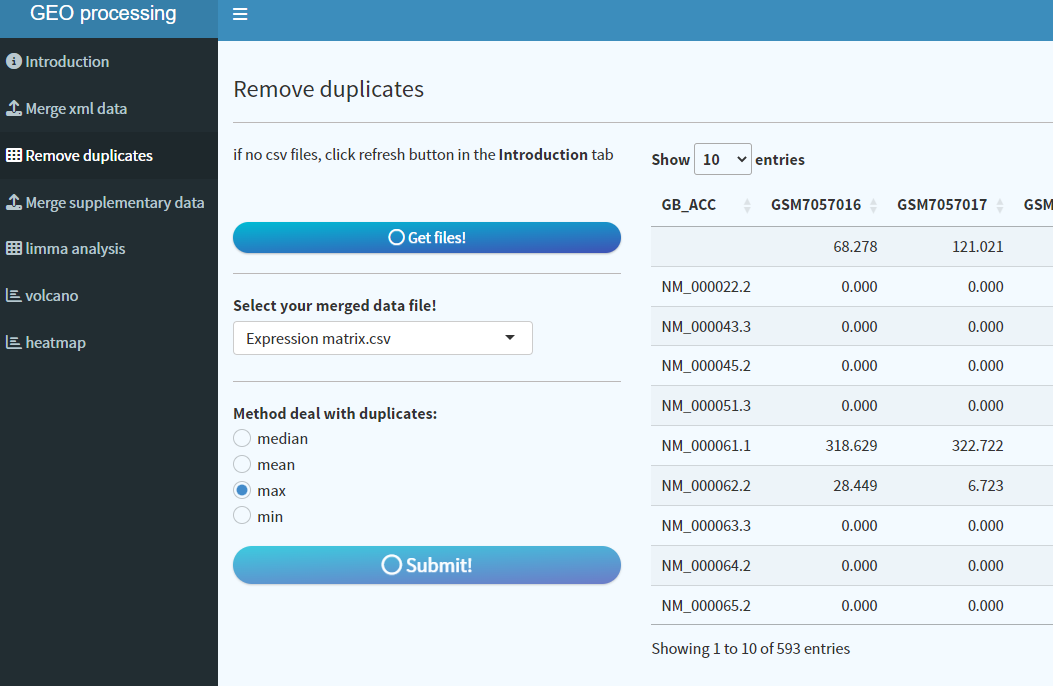
运行结束,数据自动保存至设置目录下的results文件夹中。
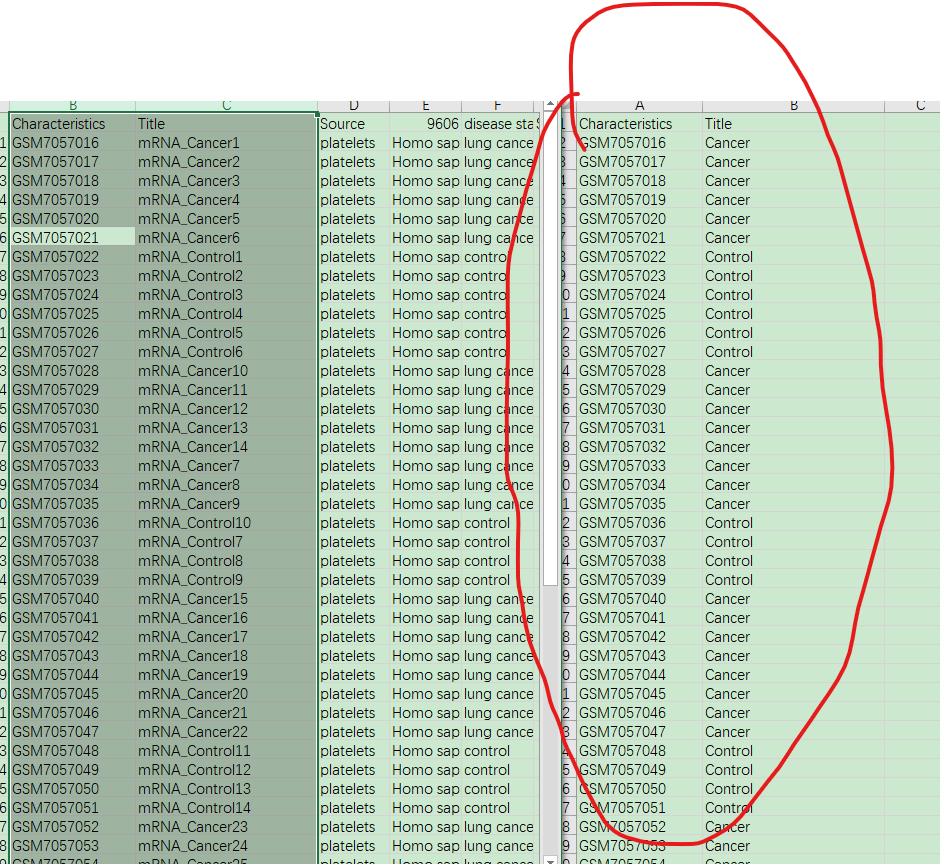
7. 使用limma包进行差异分析之前,要设置一下分组,可以打开目录下的sample information文件参考设置分组,如下图,右边是分组文件,目前该APP只支持两组的差异分析,如果有多组,请在分组文件中删除其他数据。将分组文件以csv或tct格式保存在results文件夹(group.csv),
PS:分组文件中,前面放置对照组,后面放置实验组,这样最终比较的结果就是实验组 VS 对照组
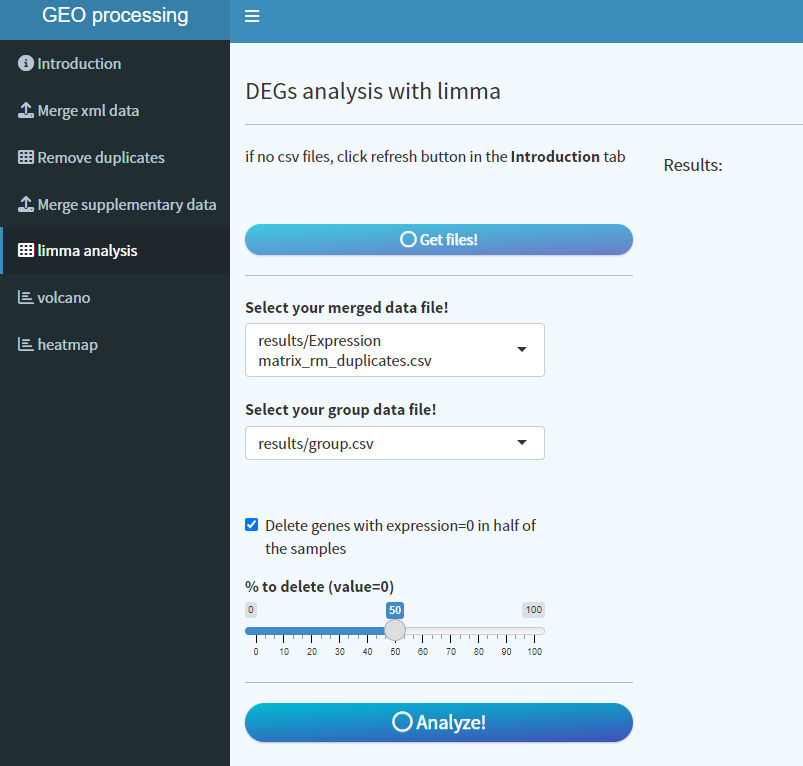
8. 进入limma analysis 界面,点击Get files,自动填充去重的数据文件以及分组文件。考虑到有些基因可能在多个样本中检测缺失,及表达为0,为避免影响分析结果,可以删除这些基因。设置完成,点击Analyze!等待片刻,即可完成分析,完成之后结果会自动保存到results文件夹,也可以手动保存到其他位置。
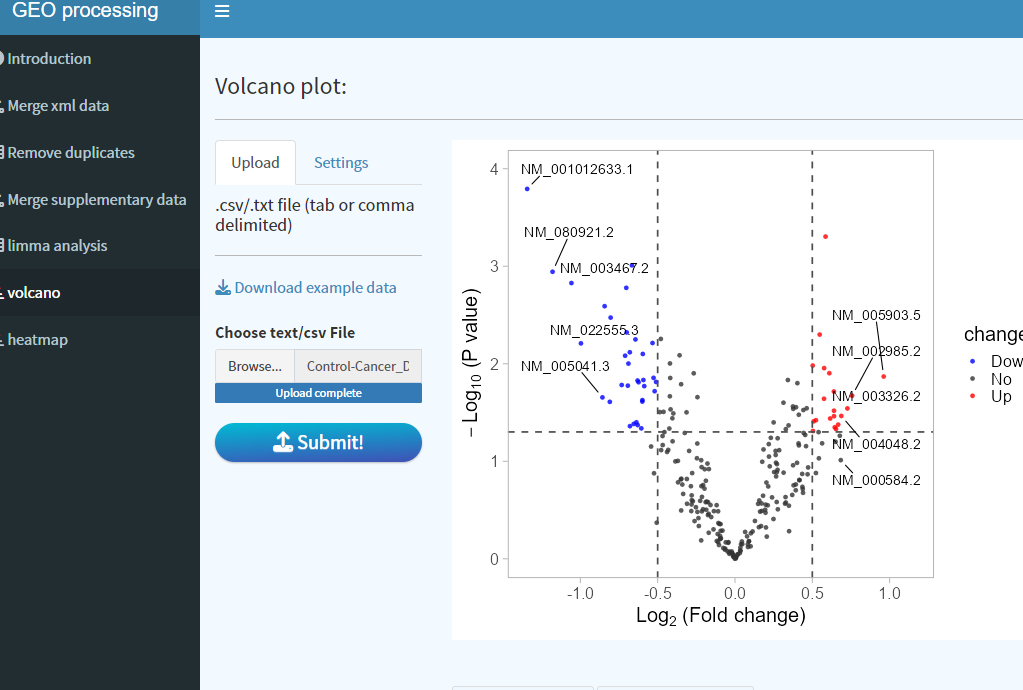
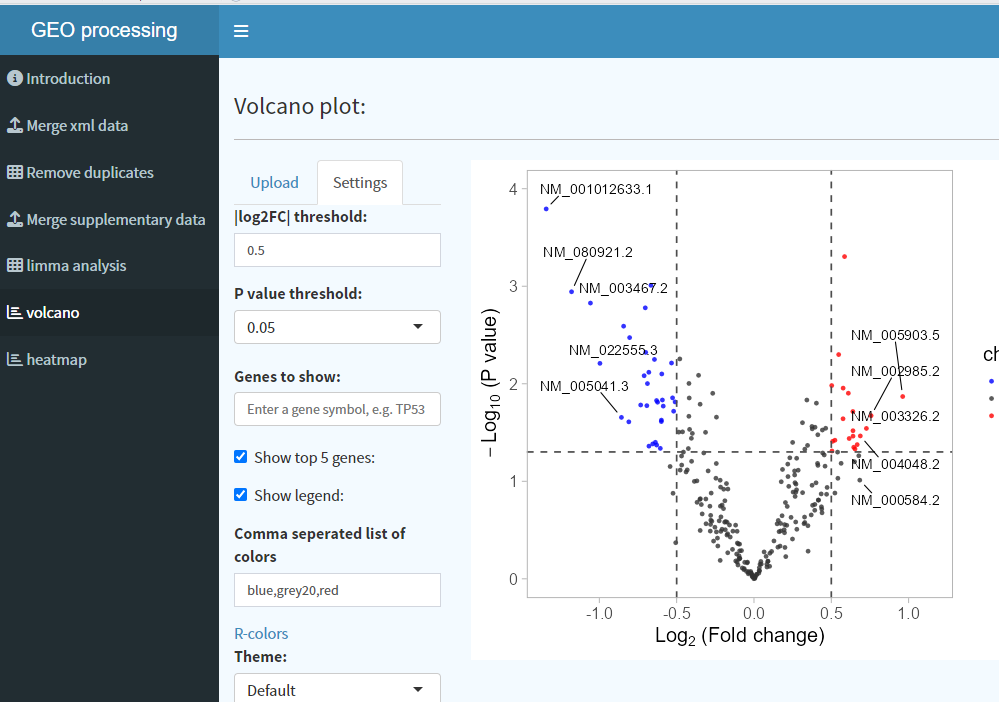
9. 火山图绘制
Browse选择limma差异分析结果文件,点击Submit即可以默认参数绘制火山图,如需修改阈值,请至setting界面,比如对于本案例,logFC改成0.5并且勾选show top 5以显示前5个上调和下调的基因。
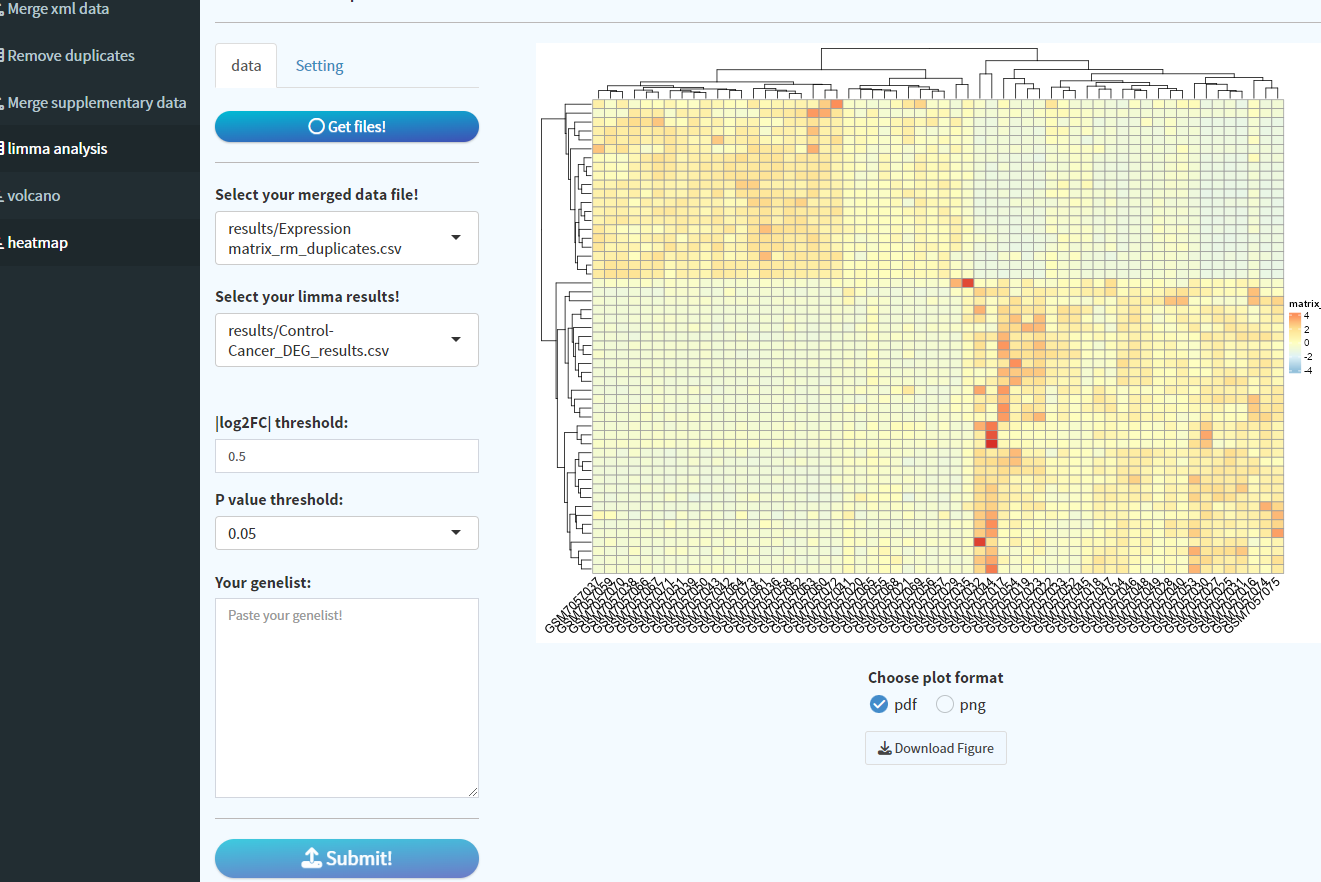
10. 热图绘制
点击Get files!自动填充表达矩阵以及差异分析结果,一般绘制热图会选择差异表达基因,同上火山图,咱们设置logFC = 0.5,点击Submit,即以默认参数得到热图:
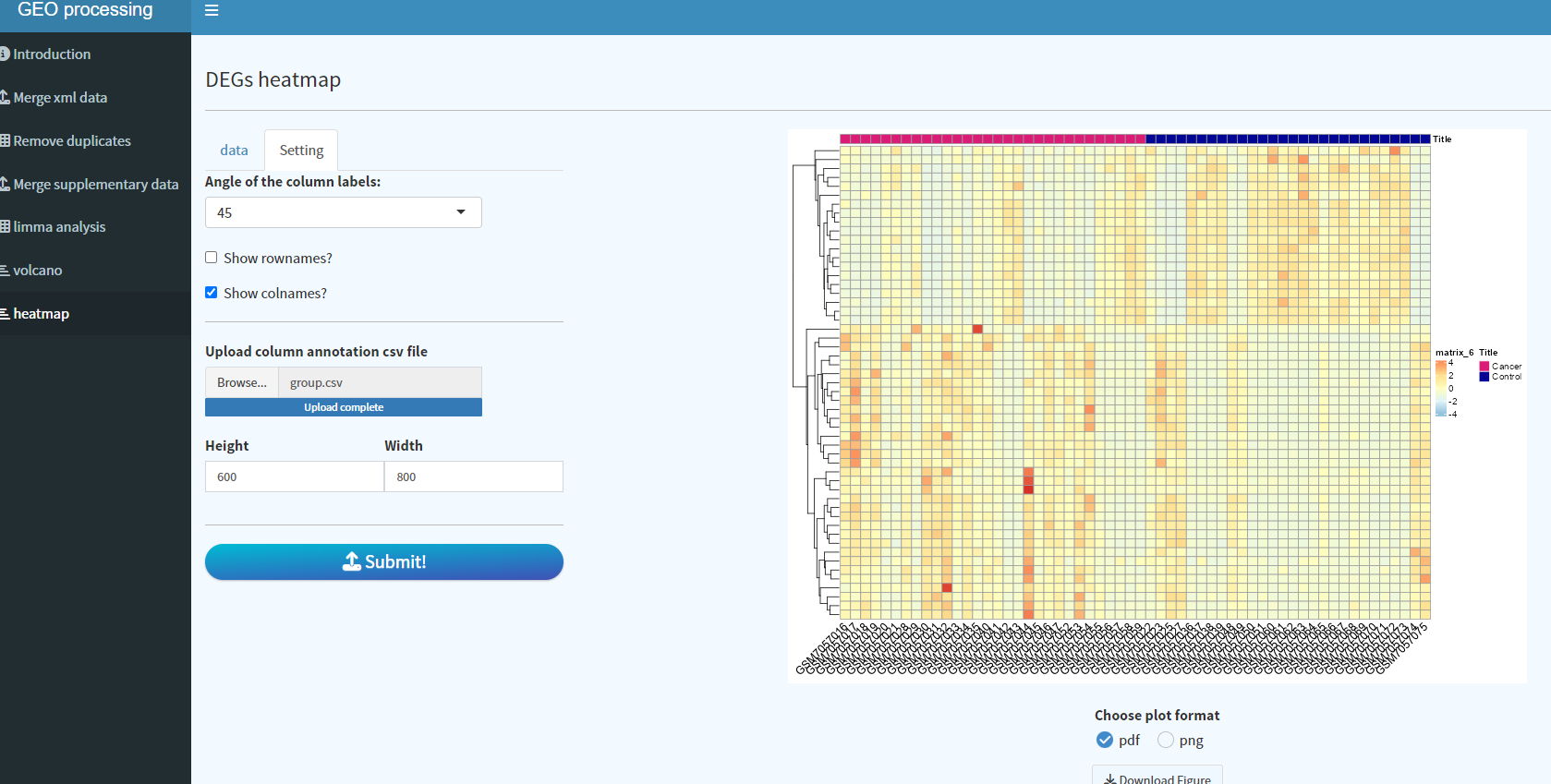
Setting界面可以修改相关参数,也可以上传样本注释信息,比如此处以差异分析的group文件作为分组注释文件上传,即可得到带有样本注释的热图:
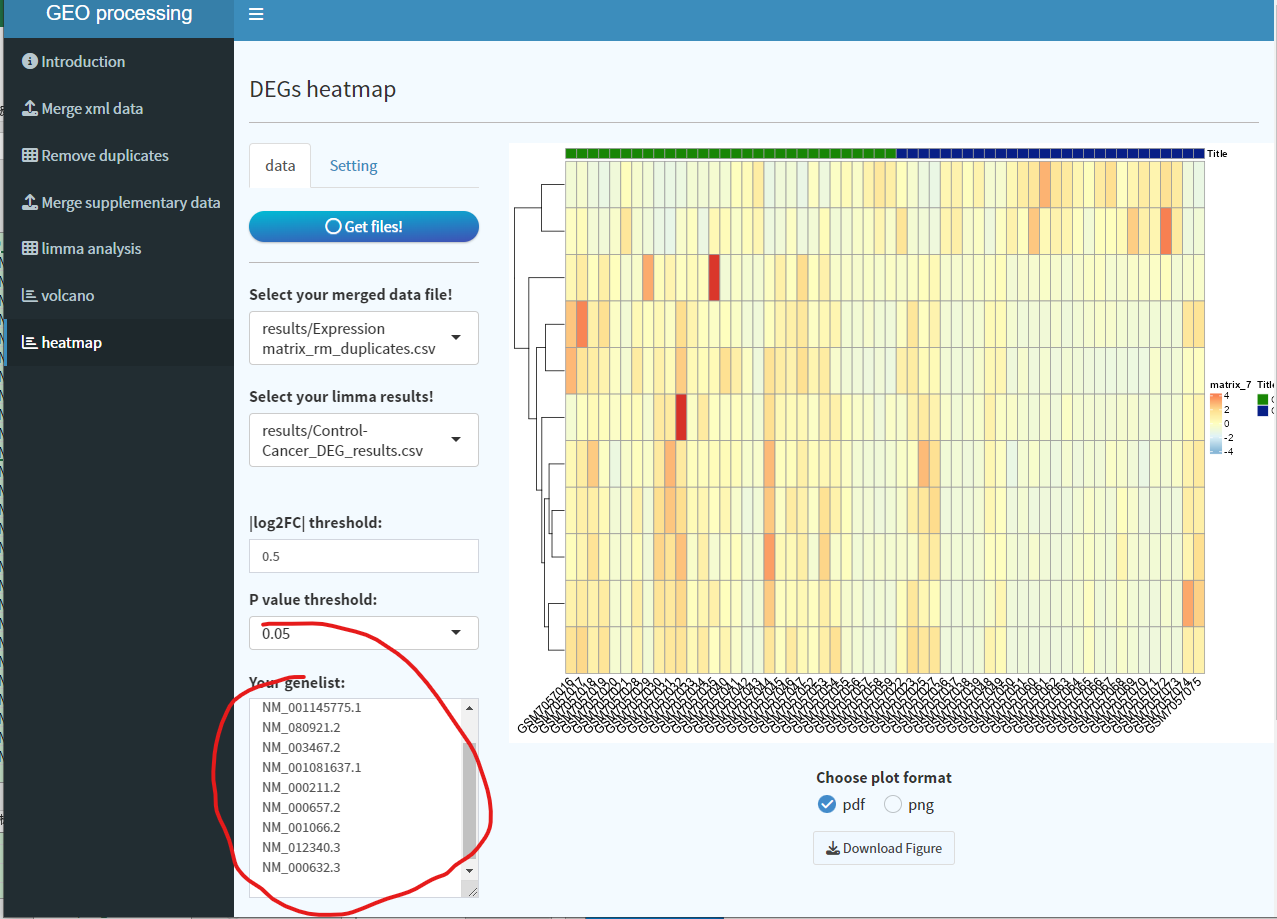
此外,也可以针对感兴趣的基因集进行热图绘制,在上述your genelist文本框中逐行输入基因名字即可:
二、GEO测序数据下载及分析
1. 对于多数测序数据,如GSE223037,作者将标准化之后的数据作为补充材料上传,此时我们就免去数据整合处理,下载直接用,根据样本信息构建分组文件。
然后在小程序中设置工作目录,转导limma差异分析界面同上进行操作。
注意,务必检查下载的矩阵中是否有多于列,比如这个数据集,我们需要删除一列:EnsemblID或GeneSymbol,如果分析时提示有重复值,同上进行去重操作。
另外,Excel文件需要另存为txt或csv在进行分析。
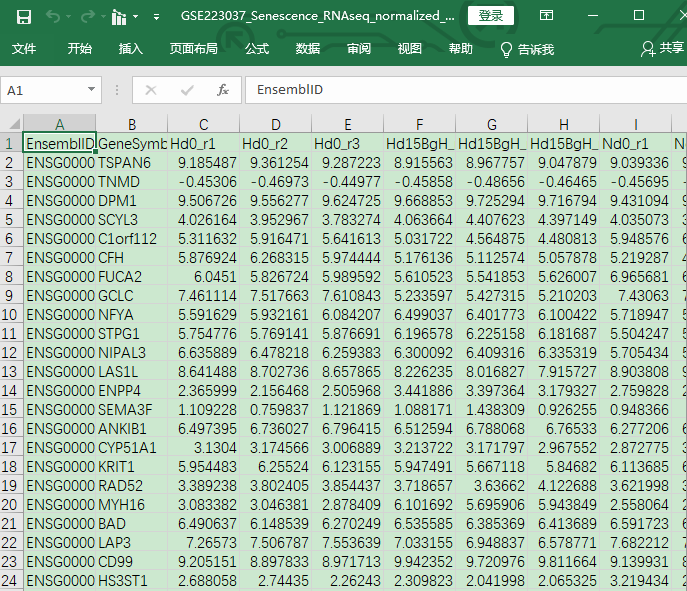
2. 对于一些测序数据,作者提供的是每个样本单独的文件,此时我们需要下载整合,如下图:GSE171807
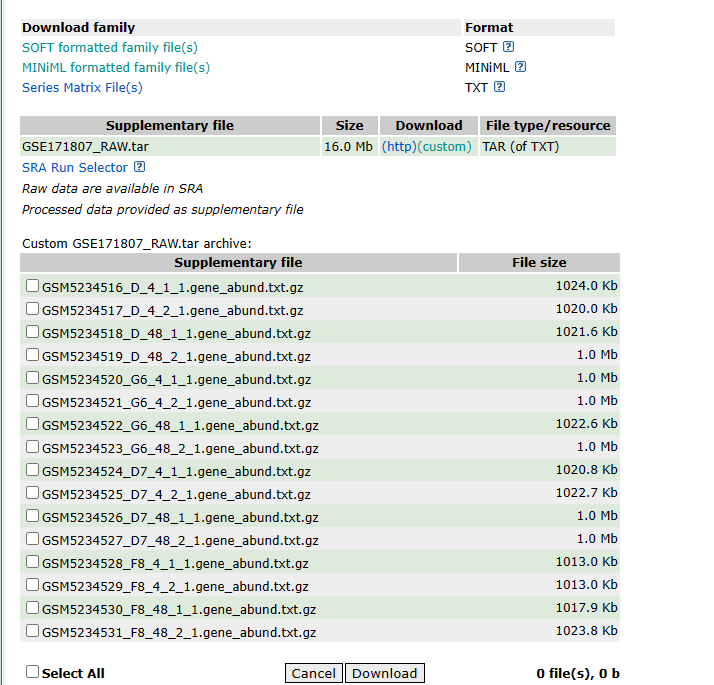
首先同上芯片下载MINIML文件,解压之后只有一个xml文件,需要根据这个提取样本信息,然后下载supplementary file,全部勾选下载到前面解压的文件夹中。
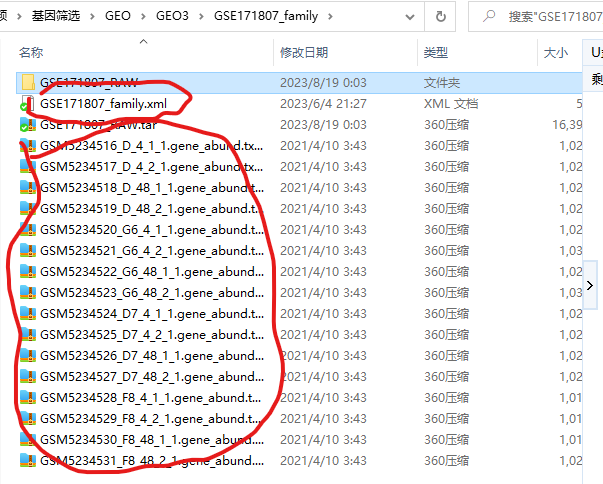
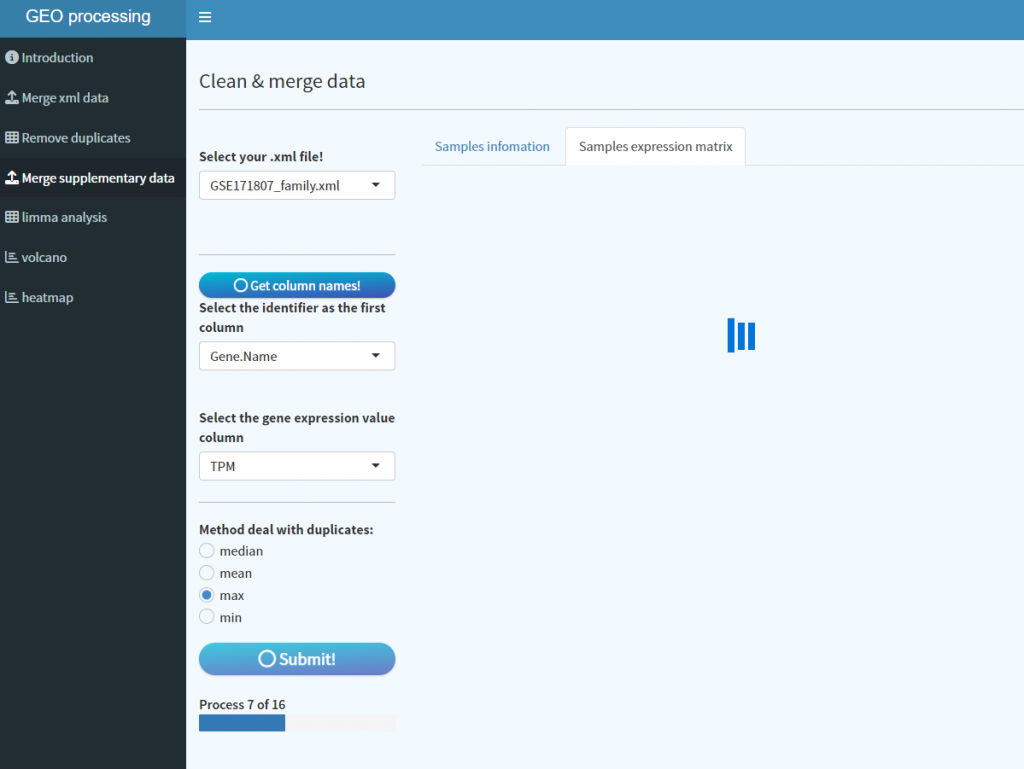
复制文件夹路径,粘贴到小程序中,点击refresh!进入Merge supplementary data界面,同样自动填充xml文件,点击get column names,即可获得单个样本数据中的列名,接下来下拉选择我们需要的列,比如这里第一列为基因名字,第二列为TPM作为表达数据。
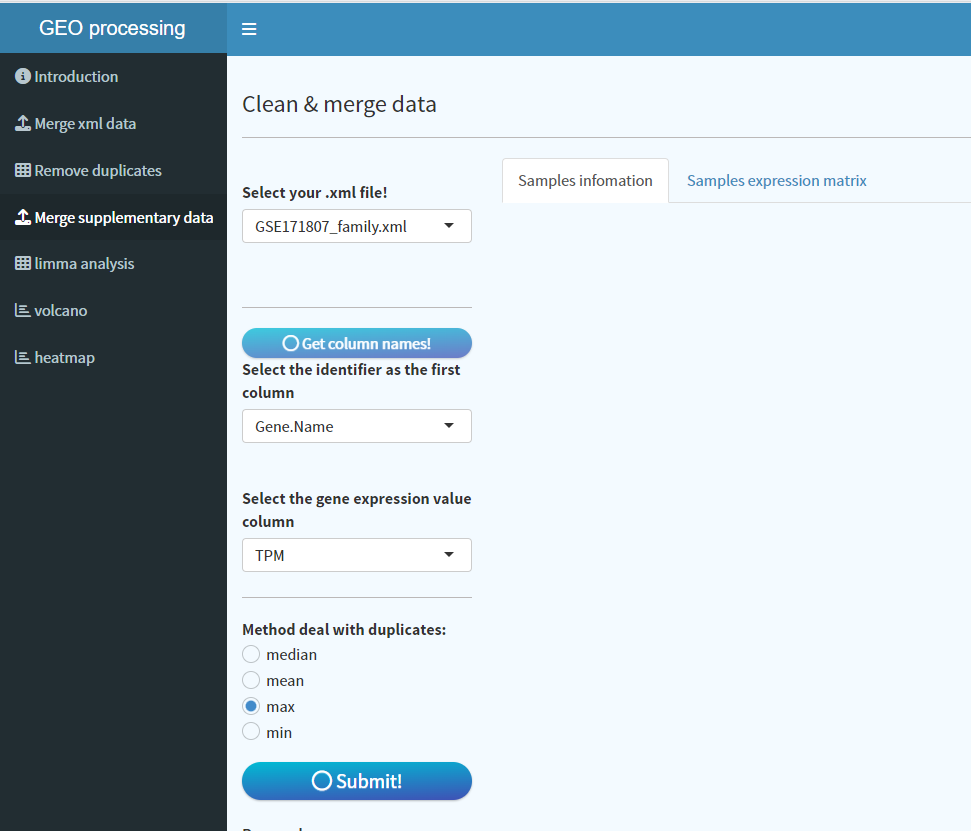
与前面芯片数据不一样的是,这边对单个样本数据进行去重处理,选择去重方法后点击Submit,即可同上开始数据整合以及样本信息整理,同上自动保存到目录下,其余操作类似,不过多赘述,这个数据无需再次进行去重处理。
挺好的 实用 简单 怎么获得该小程序?可对外出售?谢谢
你好,在这里:
https://www.jingege.wang/bilibili-code/
您好,GEO小程序为什么在R语言中运行不了
您好 有问题加我微信,不能运行就是包没安装好